L'AIOps Révolutionne les Opérations : Vers la Prédictivité et l'Autonomie
Vous avez déjà ressenti cette impression de noyade face à des milliers de lignes de logs après un incident en production ? Ce flux incessant d'alertes qui, au final, crée plus de bruit que de signal ? Ce sentiment est le symptôme d'une complexité qui dépasse désormais notre capacité humaine à réagir. C'est précisément ici que l'AIOps entre en scène, non pas comme un simple outil, mais comme un changement de paradigme fondamental.
Déconstruire le concept : Qu'est-ce que l'AIOps ?
Loin d'être un simple mot à la mode, l'AIOps (Artificial Intelligence for IT Operations) désigne l'application de l'intelligence artificielle, et plus spécifiquement de l'apprentissage automatique (Machine Learning), aux opérations informatiques. L'idée centrale est de passer d'une supervision réactive, où l'on attend qu'un problème survienne pour le corriger, à une gestion proactive et prédictive des infrastructures et des applications.
Concrètement, une plateforme AIOps ingère des volumes massifs de données provenant de sources hétérogènes : logs, métriques, traces applicatives, tickets d'incidents. Ensuite, ses algorithmes analysent ces données en temps réel pour détecter des schémas anormaux, corréler des événements apparemment sans lien et identifier la cause racine d'un problème bien avant qu'il n'impacte les utilisateurs finaux.
Les trois piliers fonctionnels de l'AIOps
Pour bien saisir sa puissance, il faut penser l'AIOps comme un processus en trois temps : observer, engager et agir. Cette boucle vertueuse permet de transformer le chaos des données brutes en actions intelligentes et automatisées, libérant ainsi les équipes opérationnelles des tâches répétitives et à faible valeur ajoutée.
- Observer : La première étape consiste en une collecte massive et centralisée de toutes les données opérationnelles. On parle ici de tout ce qui compose l'Observabilité d'un système, des métriques CPU aux traces distribuées en passant par les logs applicatifs et les événements de sécurité.
- Engager : C'est le cœur de l'intelligence. Les moteurs de Machine Learning et de Big Data analysent les données collectées pour séparer le signal du bruit. Ils réalisent une corrélation d'événements, une détection d'anomalies statistiques et une Analyse Causale (Root Cause Analysis) pour identifier l'origine réelle d'une défaillance.
- Agir : Sur la base des analyses, la plateforme peut déclencher des actions correctives. Cela peut aller de la simple notification enrichie envoyée à la bonne équipe, à l'exécution de runbooks d'automatisation pour redémarrer un service, scaler une infrastructure ou bloquer une adresse IP malveillante.
Monitoring traditionnel vs AIOps : Le saut quantique
Il est crucial de ne pas confondre l'AIOps avec les outils de monitoring classiques. Le monitoring traditionnel se base sur des seuils statiques que vous définissez manuellement. L'AIOps, lui, apprend le comportement "normal" de votre système et détecte les déviations, même les plus subtiles. C'est la différence entre une alarme incendie qui se déclenche quand la maison brûle et un système qui vous prévient d'un court-circuit avant même la première étincelle.
| Critère | Monitoring Traditionnel | AIOps |
|---|---|---|
| Approche | Réactive (basée sur des seuils fixes) | Proactive et Prédictive (basée sur l'apprentissage) |
| Source de données | Silos de données (métriques, logs séparés) | Agrégation de données hétérogènes |
| Détection | Manuelle, basée sur des règles prédéfinies | Automatique, détection d'anomalies dynamiques |
| Analyse Causale | Humaine, nécessite une expertise tribale | Assistée par l'IA, corrélation d'événements |
| Automatisation | Limitée à des scripts simples | Workflows complexes et remédiation autonome |
Anatomie d'un pipeline AIOps en pratique
Comprendre la théorie, c'est bien. Mais pour vraiment saisir la portée de l'AIOps, il faut visualiser comment les données circulent et sont transformées. L'architecture d'un tel système est conçue pour transformer un flot de données brutes en décisions opérationnelles claires et rapides.
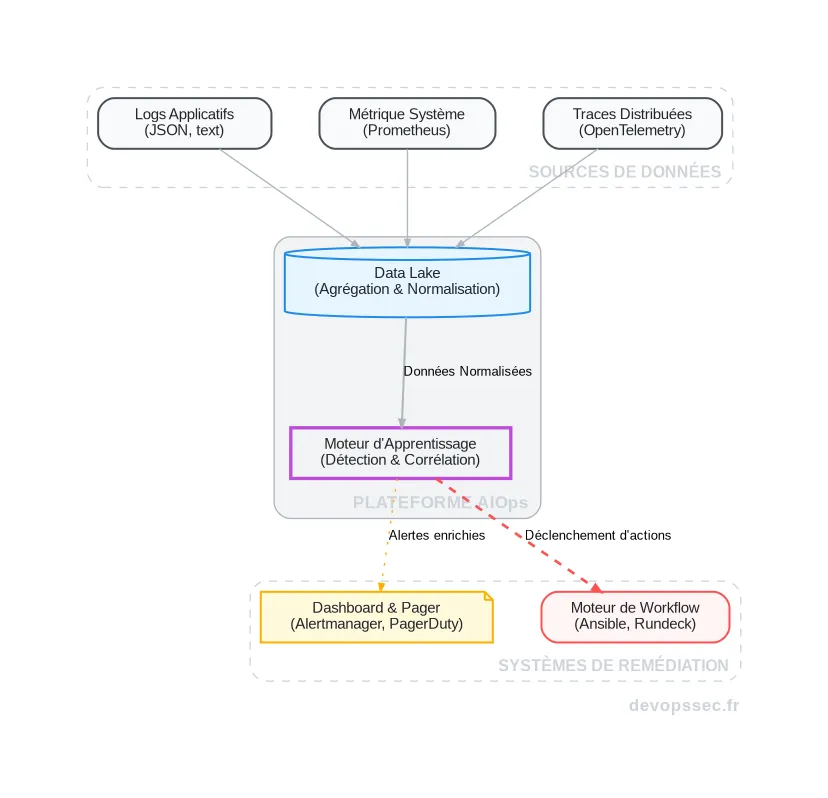
Configurer la collecte de données
Tout commence par une collecte de données exhaustive et de qualité. Sans un carburant de bonne qualité, le moteur d'Apprentissage Automatique (Machine Learning) ne produira que des résultats médiocres. C'est le fameux principe du "Garbage In, Garbage Out". Chaque source de données, qu'il s'agisse de vos serveurs Kubernetes, de vos bases de données ou de vos applications, doit être équipée d'un agent capable de formater et d'expédier les informations vers la plateforme centrale.
Voici à quoi pourrait ressembler un extrait de configuration d'un agent de collecte de logs, comme Vector, pour récupérer les logs d'un conteneur et les enrichir avec des métadonnées Kubernetes avant de les envoyer vers un data lake.
# Fichier de configuration : vector.yaml
sources:
kubernetes_logs:
type: "kubernetes_logs"
# Auto-découverte des pods à surveiller
glob_minimum_cooldown_ms: 15000
transforms:
add_metadata:
type: "remap"
inputs:
- "kubernetes_logs"
# Ajoute les labels du pod aux métadonnées du log
source: |-
.kubernetes.pod_labels = {{kubernetes.pod_labels}}
.message = .message
sinks:
aiops_platform:
type: "http"
inputs:
- "add_metadata"
uri: "https://ingest.my-aiops-platform.com"
encoding:
codec: "json"La qualité avant la quantité
Ne vous contentez pas de tout envoyer. Avant d'ingérer une nouvelle source de données, posez-vous la question de sa pertinence. Des données structurées et enrichies (comme l'ajout de labels Kubernetes) auront infiniment plus de valeur pour les algorithmes d'analyse que des logs textuels bruts.
Les angles morts de l'AIOps : Coûts, complexité et confiance
Adopter l'AIOps n'est pas une solution miracle. C'est un projet de transformation profond qui comporte son lot de défis. Ignorer ces aspects reviendrait à naviguer en pleine tempête sans carte ni boussole. Il est donc essentiel de les aborder avec lucidité avant de se lancer.
Le premier obstacle, et non des moindres, est la complexité inhérente à ces systèmes. Mettre en place et maintenir une plateforme AIOps efficace requiert des compétences pointues qui sont rares et donc coûteuses. Vous aurez non seulement besoin d'ingénieurs DevOps, mais aussi de Data Scientists capables de comprendre, d'ajuster et d'interpréter les modèles d'apprentissage automatique.
De plus, le coût financier peut être conséquent. Entre les licences des plateformes commerciales, l'infrastructure de calcul nécessaire pour traiter des pétaoctets de données et les salaires des experts, la facture peut vite grimper. Il faut donc s'assurer que le retour sur investissement, en termes de réduction du temps moyen de résolution (MTTR) et d'amélioration de la disponibilité, soit au rendez-vous.
Enfin, la question de la confiance est primordiale. Certains modèles de Machine Learning peuvent se comporter comme des "boîtes noires", rendant leurs décisions difficiles à expliquer. Autoriser un système automatisé à effectuer des changements en production (comme un rollback ou un redémarrage de service) sur la base d'une décision opaque peut être un risque que toutes les organisations ne sont pas prêtes à prendre.
Conclusion : L'aube d'une nouvelle ère pour les opérations
Malgré les défis, l'AIOps représente sans aucun doute l'avenir des opérations IT. Dans un monde où les architectures microservices et le cloud natif génèrent une complexité exponentielle, les approches humaines traditionnelles ne suffisent plus. L'intelligence artificielle n'est plus une option, mais une nécessité pour maintenir des systèmes résilients et performants.
L'objectif n'est pas de remplacer les ingénieurs humains, mais de les augmenter. En déléguant la détection et la remédiation des problèmes courants à la machine, l'AIOps libère un temps précieux pour que les équipes puissent se concentrer sur l'innovation, l'architecture et la résolution de problèmes complexes à forte valeur ajoutée. Nous entrons dans une ère où l'IT devient moins réactive et plus stratégique, guidée par la donnée et l'intelligence prédictive.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
25 commentaires
D'ailleurs, pour ceux qui veulent tester, commencez par corréler les alertes de votre outil de monitoring avec les événements de vos pipelines CI/CD.
C'est le point de départ le plus simple pour voir la puissance de la corrélation sans tout casser en prod.
C'est pour ça que l'IA doit être assistée. Elle pointe vers des suspects probables basés sur des patterns historiques.
C'est une aide à la décision, pas un remplaçant de l'ingénieur. Si tu cherches la vérité absolue, tu vas être déçu.
Je reste sceptique sur l'analyse causale automatique. J'ai jamais vu un outil trouver la root cause tout seul sans se tromper.
C'est là que l'abstraction via des outils comme Vector brille. Tu standardises le format de sortie peu importe la source.
L'important c'est de garder un schéma de log unique en sortie de ton pipeline de collecte.
Quelqu'un a déjà tenté de déployer ça sur du multi-cloud ? La config de collecte doit être un enfer.
C'est de l'automatisation, pas de l'AIOps. L'AIOps implique une couche de ML pour analyser et corréler avant d'agir.
Si ton trigger est basé sur une règle fixe, c'est du monitoring classique amélioré.
On utilise des fonctions Lambda pour trigger des actions basées sur des logs d'erreurs. C'est considéré comme de l'AIOps ?
Il n'est pas mort, il est dépassé. T'auras toujours besoin de seuils simples pour les trucs évidents comme "disque plein à 95%". L'AIOps c'est pour tout le reste, la complexité invisible.
Le tableau comparatif est sympa. Le monitoring traditionnel est mort, je suis d'accord.
Chiffre le coût de tes incidents (temps dev + downtime). Si tu réduis tes incidents de 30% par mois, le ROI est vite calculé.
Mais faut être honnête sur les coûts de maintenance, sinon tu te fais défoncer au prochain audit.
Comment on justifie le coût d'une telle plateforme auprès du CTO ? C'est ça le vrai blocage.
Prometheus c'est la base pour les métriques. Tu peux utiliser ses exporters pour alimenter ton pipeline AIOps, mais l'IA va surtout t'aider à corréler ces métriques avec des événements de déploiement.
Est-ce que vous avez des retours sur l'intégration avec des outils comme Prometheus ?
Exactement. Tu peux avoir le meilleur algo du monde, si tes logs sont non-structurés ou inconsistants, tu vas juste obtenir des corrélations débiles.
Le nettoyage, c'est 80% du taf en AIOps.
Le point sur le "Garbage In, Garbage Out" est le plus important. Tout le monde veut de l'IA mais personne ne veut nettoyer ses logs.
L'agent est léger, mais il faut le dimensionner. Utilise des
DaemonSetavec des ressources limitées.Si ton agent commence à bouffer trop de CPU, c'est que ta config de filtrage est mal faite. Filtre à la source, pas au sink.
Vous parlez de
vector.yaml, mais ça scale comment quand on a des milliers de nodes ? La latence de l'agent peut devenir un problème.Jamais en full auto au début. Faut commencer par le mode "human-in-the-loop". L'IA propose, l'humain valide. Tu automatises totalement seulement quand tu as confiance dans le taux de faux positifs.
C'est pas de la magie, c'est de la gestion de risque.
Et la sécurité dans tout ça ? On laisse une IA modifier des
ConfigMapou redémarrer des pods en prod ? Ça me semble être une faille béante.Content que ça aide. Le secret c'est vraiment le mapping dès la source. Si tu laisses passer des logs bruts sans labels k8s dans ton pipeline, tu ne pourras jamais faire d'analyse causale propre.
J'ai testé
vector.yamlcomme indiqué. L'enrichissement avec lespod_labels, ça change la vie pour filtrer le bruit, merci.C'est le problème des seuils statiques classiques. L'AIOps sérieux utilise des modèles qui s'adaptent dynamiquement sur des fenêtres glissantes.
Par contre, si ton cycle de déploiement est trop court et que ton modèle n'a pas assez d'historique, faut passer sur des modèles pré-entraînés sur des topologies similaires. Sinon, tu vas juste spammer tes on-call.
C'est beau sur le papier, mais comment on gère le cold start du ML ? À chaque nouveau microservice déployé, on repart de zéro avec des alertes faussement positives non ?
Le MTTR baisse si tu arrêtes de traiter tes logs comme un dump poubelle. L'article est clair : si tu n'injectes pas de contexte, ton IA ne fera que corréler du bruit.
Le gain arrive quand tu corrèles les traces distribuées avec les métriques système. Si tu fais pas ça, t'as juste une alerte plus jolie, pas une solution.
Encore un article sur l'AIOps. J'ai vu trop de boîtes cramer leur budget là-dedans pour des résultats invisibles. Tu promets quoi concrètement sur la réduction du MTTR ?