Jumeaux Numériques : La Révolution des Opérations Prédictives
Et si vous pouviez tester un correctif de sécurité critique sur une réplique exacte de votre production, en plein pic de trafic, sans jamais risquer la moindre interruption de service ? Ce n'est plus de la science-fiction, mais la promesse concrète des jumeaux numériques appliqués au monde des opérations IT.
Oubliez l'image des moteurs d'avion modélisés en 3D. Dans notre univers, un Jumeau Numérique est une réplique virtuelle, vivante et dynamique de votre infrastructure, de vos applications et de leurs dépendances. Il est alimenté en permanence par les données télémétriques du système réel, ce qui lui permet de refléter son état, son comportement et ses performances à chaque instant.
L'objectif n'est plus seulement de superviser, mais de prédire. En utilisant ce double virtuel, nous pouvons simuler des scénarios, anticiper des pannes et optimiser les ressources avec une précision qui était jusqu'alors inaccessible avec les environnements de staging traditionnels.
Les Fondations d'un Double Virtuel Efficace
Construire un jumeau numérique ne se résume pas à dupliquer une machine virtuelle ou un cluster Kubernetes. C'est un processus organique qui repose sur la captation et l'interprétation d'un flux de données constant, transformant le bruit informationnel en intelligence actionnable.
Le Rôle Central de l'Observabilité
Le carburant de tout jumeau numérique, c'est la donnée. Sans une stratégie d'Observabilité mature, votre jumeau ne sera qu'une coquille vide, incapable de refléter la réalité de votre production. Il ne s'agit pas simplement de collecter des métriques CPU, mais de comprendre le "pourquoi" derrière le comportement d'un système.
Concrètement, cela signifie agréger trois types de signaux en temps réel depuis votre environnement de production vers le modèle virtuel qui constitue le jumeau. Ces signaux forment le triptyque de la compréhension systémique moderne.
- Les Métriques (Metrics) : Des mesures numériques quantitatives collectées à intervalles réguliers, comme l'utilisation de la mémoire, le temps de réponse d'une API ou le nombre de requêtes par seconde.
- Les Traces (Traces) : La représentation du cycle de vie complet d'une requête à travers les différents microservices de votre architecture. Elles permettent de visualiser le chemin exact et d'identifier les goulots d'étranglement.
- Les Journaux (Logs) : Des enregistrements textuels immuables d'événements discrets, utiles pour le débogage et l'analyse post-mortem d'un incident.
C'est la corrélation de ces trois sources qui donne vie au jumeau, lui permettant de répliquer non seulement l'état des composants, mais aussi les interactions complexes et les dépendances qui les régissent.
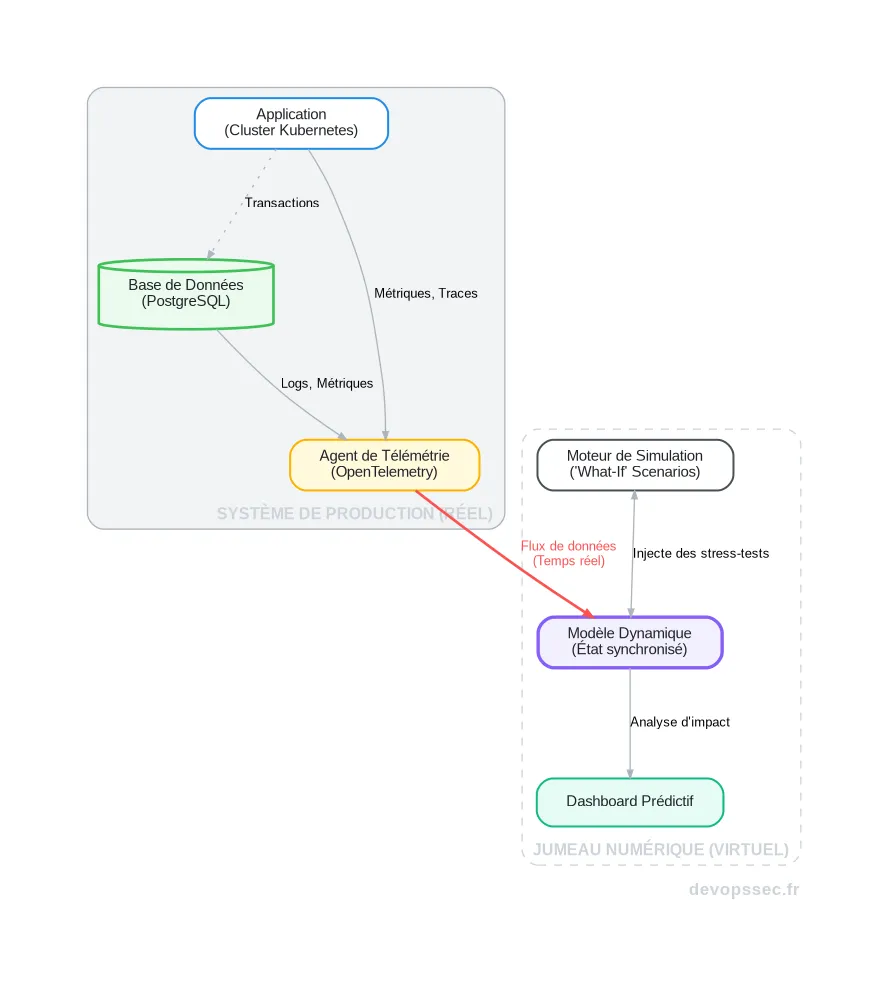
Ce schéma illustre le cœur du mécanisme : l'agent de télémétrie, déployé sur l'infrastructure de production, collecte en continu les signaux vitaux de l'application et de sa base de données. Ce flux de données est ensuite streamé vers le modèle virtuel, qui met à jour son état pour refléter parfaitement celui de son homologue réel. C'est sur ce modèle synchronisé que le moteur de simulation peut alors opérer.
Transformer le Cycle de Vie DevOps
L'adoption des jumeaux numériques transcende la simple supervision. Elle refaçonne des pans entiers de notre cycle de vie applicatif, du développement à la mise en production, en passant par la gestion des incidents.
Une CI/CD qui Prédit l'Avenir
Les pipelines de CI/CD modernes sont robustes, mais ils valident principalement le code sur des environnements de pré-production qui, avouons-le, ne sont jamais des répliques parfaites de la production. Ils ne peuvent pas simuler le trafic réel, les états de cache complexes ou les dégradations subtiles accumulées au fil du temps.
Avec un jumeau numérique, une nouvelle étape s'insère dans le pipeline : le " déploiement simulé ". Avant de pousser une nouvelle version sur l'environnement réel, le pipeline la déploie sur le jumeau numérique, qui est à cet instant précis une copie conforme de l'état de la production.
On peut alors bombarder cette version avec une simulation de trafic réaliste pour mesurer son impact sur les performances, la latence et la consommation de ressources avant même que la première ligne de code n'atteigne les serveurs de production.
jobs:
deploy-to-digital-twin:
name: Déploiement et validation sur le Jumeau Numérique
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Build and Push Docker Image
run: |
docker build -t gcr.io/my-project/app:{{ github.sha }} .
docker push gcr.io/my-project/app:{{ github.sha }}
- name: Deploy to Digital Twin Cluster
uses: steebchen/kubectl@v2.0.0
with:
config: {{ secrets.KUBE_CONFIG_TWIN }}
command: apply -f k8s/deployment.yaml
- name: Run Predictive Load Test
run: ./scripts/run-simulation.sh --traffic=peak --duration=10m
- name: Analyze Impact Report
run: ./scripts/check-report.sh --threshold=5%Optimisation des Coûts par la Simulation
Une des questions les plus complexes pour un ingénieur SRE ou FinOps est le dimensionnement des ressources. Comment savoir si une instance plus puissante est vraiment nécessaire ou si une optimisation logicielle suffirait ? Les jumeaux numériques offrent un terrain de jeu sans risque pour répondre à ces questions.
En créant des scénarios "what-if", on peut modéliser l'impact d'un changement d'infrastructure ou d'une augmentation de charge pour prendre des décisions basées sur des données simulées, mais réalistes.
| Scénario Simulé sur le Jumeau | Configuration Virtuelle | Latence API (p99) | Coût Projeté / Heure |
|---|---|---|---|
| Charge de base actuelle | 2x pods (type n2-standard-4) | 85ms | 0.26€ |
| Simulation "Black Friday" (Trafic x5) | 2x pods (type n2-standard-4) | 1250ms (Inacceptable) | 0.26€ |
| Simulation "Black Friday" avec HPA | 8x pods (type n2-standard-4) | 110ms | 1.04€ |
| Simulation "Black Friday" avec instances plus larges | 3x pods (type n2-standard-8) | 95ms (Optimal) | 0.78€ |
Ce tableau montre qu'une simple mise à l'échelle horizontale (HPA) est efficace mais coûteuse. En revanche, la simulation révèle qu'utiliser moins de pods mais plus puissants offre un meilleur compromis entre performance et coût, une conclusion difficile à atteindre sans une telle modélisation.
Complexité et Risques : La Face Cachée du Miroir
Malgré ses promesses, l'implémentation d'un jumeau numérique n'est pas un projet trivial. Il comporte des défis techniques et organisationnels importants qu'il faut anticiper pour ne pas transformer le rêve prédictif en cauchemar opérationnel.
Le principal danger est la Dérive de Modèle (Model Drift). Si le flux de données télémétriques est interrompu ou si le modèle virtuel n'est pas mis à jour assez rapidement, il cesse d'être un "jumeau" pour devenir un simple "cousin éloigné". Les simulations menées sur un modèle désynchronisé produiront des résultats au mieux inutiles, au pire trompeurs, pouvant conduire à de mauvaises décisions.
Attention aux coûts de la télémétrie
Maintenir un jumeau numérique génère un volume de données colossal. Les coûts liés au stockage des logs, à l'ingestion des métriques et à la puissance de calcul nécessaire pour faire tourner les simulations peuvent rapidement exploser si ils ne sont pas maîtrisés et provisionnés dès le début du projet.
Enfin, la complexité de l'outillage est un facteur à ne pas sous-estimer. Mettre en place et maintenir la plomberie logicielle pour collecter, transporter, stocker et analyser ces données en temps réel demande une expertise pointue en ingénierie de la donnée et en plateformes d'observabilité.
Conclusion : Des Opérations Réactives aux Opérations Prédictives
Le jumeau numérique représente un changement de paradigme fondamental pour le DevOps. Il nous fait passer d'une posture réactive, où nous analysons les problèmes après qu'ils se sont produits, à une posture proactive et même prédictive, où nous pouvons désamorcer les bombes avant qu'elles n'explosent.
Ce n'est pas une solution magique, mais un outil stratégique puissant qui, lorsqu'il est bien maîtrisé, offre un niveau de contrôle et de compréhension de nos systèmes sans précédent. En nous permettant de tester l'inattendu et de simuler l'avenir, il nous rapproche un peu plus du but ultime : une infrastructure résiliente, performante et, peut-être un jour, entièrement autonome.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
20 commentaires
Les tests unitaires ne voient pas les problèmes de performance dus à la fragmentation de la mémoire ou aux conflits de lock en base de données. Le jumeau, lui, les voit. C'est pour ça qu'on est passé sur cette approche :
Franchement, je préfère passer ce temps à améliorer mes tests unitaires et mes
canary deployments. C'est plus fiable et moins cher.On utilise des
gitopscontrollers. L'état du jumeau est dérivé du même repo que la prod. Si le repo change, le jumeau est mis à jour automatiquement.Le
model driftest inévitable. Comment vous gérez les changements de config typeconfigmapousecretqui ne sont pas forcément tracés par les métriques ?Quelqu'un a déjà essayé de faire ça avec
terraform? J'ai peur que l'état devienne ingérable avec deux environnements synchronisés en permanence.Le risque zéro n'existe pas. Le jumeau est un outil d'aide à la décision, pas un remplaçant de la vigilance humaine.
J'aime bien l'idée, mais ton exemple
kubectl applyme fait peur. Si le jumeau est mal configuré, tu risques d'avoir des faux positifs et de déployer en prod un truc qui va tout casser.Tu parles d'optimisation de coûts, mais tu oublies le coût humain. Qui gère le monitoring du monitoring ? C'est le serpent qui se mord la queue.
D'où l'importance d'intégrer ça dans la CI. Si le test sur le jumeau échoue à cause d'une incompatibilité, le pipeline
gitlab-ci.ymlbloque le merge. C'est du shift-left radical.J'ai bossé sur un truc similaire. Le problème c'est pas la technique, c'est la maintenance des mocks. Dès qu'un dev modifie une route API, le jumeau numérique devient faux. On passe plus de temps à maintenir le jumeau qu'à dev le produit.
C'est une usine à gaz. Pour 99% des boîtes, un bon environnement de staging avec des données anonymisées suffit. Pourquoi vouloir complexifier l'infra pour des cas marginaux ?
C'est du replay de logs transformé en scénarios
k6. On capture le trafic réel avec unsidecar, on nettoie les PII et on le réinjecte.J'ai regardé ton script
run-simulation.sh. Ça tourne comment au juste ? Si c'est juste unabou unk6balancé à l'arrache, ça ne simule pas le comportement utilisateur réel.Tu ne partages jamais la base de prod. Tu utilises des snapshots ou des outils comme
doltpour versionner tes données. C'est là que réside la complexité technique."Opérations prédictives"... ça sent le buzzword pour justifier un
helmchart trop complexe. Comment tu gères les effets de bord d'une base de données partagée pendant tes tests ?Pour les dépendances, on utilise des outils de service mesh pour router le trafic vers des instances isolées. C'est pas gratuit, mais c'est le prix à payer pour de la vraie simulation.
Exactement. On a tenté un truc similaire avec des outils de shadow traffic. Résultat : on a explosé notre budget
cloudjuste en ingestion de logs. Le ROI est plus que douteux.Le coup du
deployment.yamlpoussé sur le jumeau, c'est bien joli sur le papier. Mais quid des dépendances externes ?Si mon app tape une API tierce en prod, dans mon jumeau elle tape quoi ? Un mock ? Si c'est un mock, t'as zéro valeur ajoutée sur la simulation de perf.
La dérive est réelle, je le mentionne dans l'article. La solution c'est d'automatiser la synchro avec des CRD personnalisés. Si ton infra change, le modèle doit se mettre à jour via un webhook sur ton
api-server.Encore un concept marketing pour vendre du consulting. J'ai déjà assez de mal à garder mon
prometheuscohérent avec mesk8sclusters actuels sans y ajouter une surcouche de simulation.C'est quoi la garantie que le modèle virtuel ne diverge pas au bout de 48h ?