L'Observabilité Prédictive : Bienvenue dans l'ère du "corriger avant que ça ne casse"
As-tu déjà ressenti cette montée d'adrénaline à 3 heures du matin, déclenchée par une alerte PagerDuty signalant qu'un service critique est tombé ? Nous sommes tous passés par là. Pendant des années, notre métier a consisté à réagir le plus vite possible. Mais si je te disais que cette époque est en train de se terminer ?
Aujourd'hui, nous ne nous contentons plus de regarder des dashboards qui nous disent ce qui a mal tourné. Nous construisons des systèmes qui nous préviennent de ce qui va mal tourner. C'est le changement de paradigme fondamental apporté par l'Observabilité Prédictive, une discipline qui fusionne l'analyse de données en temps réel avec la puissance de l'intelligence artificielle.
L'objectif n'est plus seulement de réduire le temps moyen de résolution (MTTR), mais de carrément empêcher l'incident de se produire. C'est une véritable révolution dans notre approche de la fiabilité et de la résilience des systèmes distribués.
Des piliers classiques à l'intelligence proactive
Pour bien saisir la portée de cette évolution, il faut d'abord revenir sur les fondations de l'observabilité que tu connais bien. Le fameux triptyque Logs, Métriques et Traces a été notre boussole pendant une décennie pour naviguer dans la complexité de nos applications.
Pourtant, ces piliers ont une limite fondamentale : ils sont réactifs par nature. Ils décrivent un état passé ou présent, mais ne fournissent que très peu d'indices sur le futur. On passe notre temps à chercher une aiguille dans une botte de foin après que l'incendie se soit déclaré.
Quand les données brutes ne suffisent plus
Imagine un cluster Kubernetes avec des centaines de microservices. La quantité de données générées est astronomique. Analyser manuellement les corrélations entre un pic de latence sur le service de paiement, une augmentation des erreurs 503 sur l'API Gateway et une saturation de la mémoire sur un pod spécifique est une tâche herculéenne, voire impossible pour un humain en temps réel.
C'est précisément là que l'approche classique montre ses limites. Nous avons des montagnes de données, mais une capacité limitée à en extraire une sagesse prédictive. L'AIOps (AI for IT Operations) intervient pour combler ce fossé, en agissant comme une couche d'intelligence au-dessus de nos outils de monitoring traditionnels.
Concrètement, l'AIOps va permettre de :
- Détecter des anomalies et des patterns invisibles à l'œil nu.
- Corréler des événements faibles provenant de sources multiples (logs applicatifs, métriques système, traces distribuées).
- Analyser les dépendances entre les services pour comprendre les effets de bord.
- Établir des lignes de base dynamiques (baselines) pour chaque service, qui s'adaptent au cycle de vie de l'application.
Le rôle central des modèles causaux profonds
Le véritable moteur de cette révolution, ce sont les modèles causaux profonds. Contrairement aux modèles de machine learning classiques qui se contentent d'identifier des corrélations ("quand A se produit, B se produit souvent aussi"), les modèles causaux cherchent à comprendre les relations de cause à effet ("A est la cause de B").
Cette distinction est cruciale. En comprenant la causalité, le système peut non seulement prédire une panne imminente mais aussi identifier sa cause racine probable, permettant une intervention ciblée bien avant que l'utilisateur final ne soit impacté.
Ces modèles apprennent en continu à partir du flux de données d'observabilité de ton système, construisant une sorte de "jumeau numérique" du comportement de ton application.
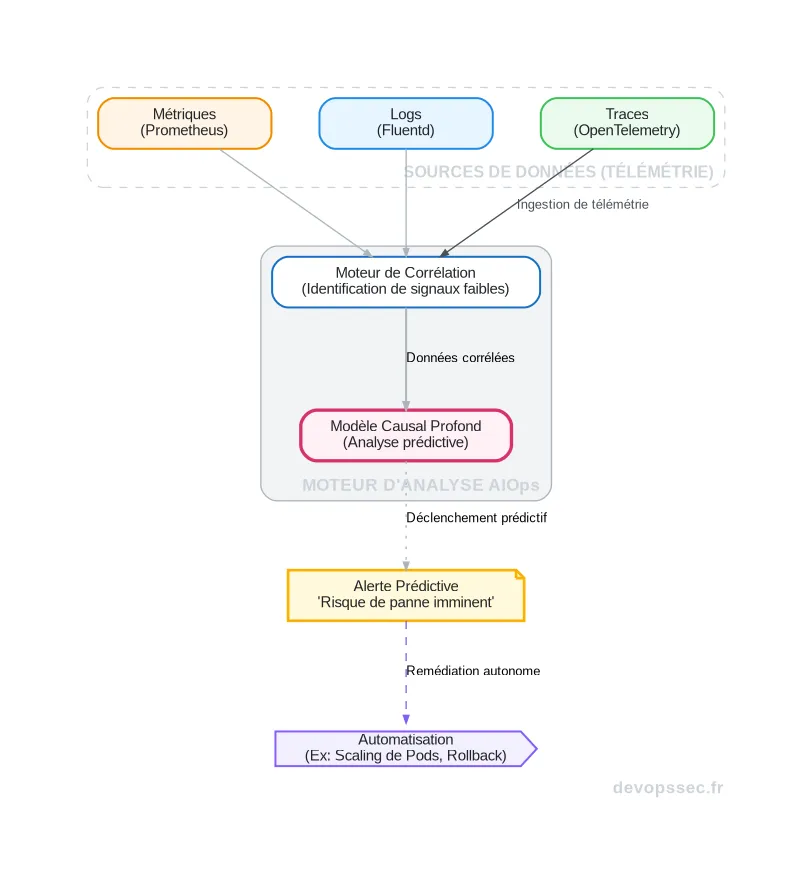
Ce schéma illustre parfaitement le parcours de la donnée. Les sources brutes de télémétrie sont d'abord ingérées et corrélées pour identifier des signaux qui, isolément, seraient insignifiants. C'est ensuite le modèle causal qui analyse ces signaux pour prédire une dégradation future et générer une alerte enrichie, qui peut même déclencher une action de remédiation automatique.
Mise en pratique : Anticiper une saturation de service
La théorie, c'est bien, mais voyons comment cela se matérialise sur le terrain. Imaginons un service de traitement de commandes qui tourne sur Kubernetes. Il a tendance à avoir des fuites de mémoire lentes sous une charge spécifique, menant à un crash du pod après plusieurs heures.
Avec une approche classique, tu recevrais une alerte quand le pod entre en état CrashLoopBackOff. Il est déjà trop tard, des commandes ont été perdues. Avec l'observabilité prédictive, le scénario est tout autre.
La qualité des données est reine
Un modèle prédictif est aussi bon que les données qu'on lui fournit. Avant de penser IA, assure-toi que ton instrumentation (via OpenTelemetry par exemple) est riche et standardisée. Des logs bien structurés en JSON et des traces complètes sont des prérequis non négociables.
La plateforme AIOps, qui observe continuellement les métriques de Prometheus, va détecter une corrélation subtile qu'un humain raterait. Elle remarque qu'une légère augmentation de la latence sur une route d'API spécifique est systématiquement suivie, 90 minutes plus tard, par une augmentation linéaire de l'utilisation de la mémoire du pod correspondant.
L'outil ne se contente pas de voir la montée de la RAM. Il a identifié le symptôme précurseur. Au lieu d'une alerte brute, il génère un rapport prédictif.
ops-ai-cli predict --service order-processor --namespace productionRésultat:
[PREDICTIVE ALERT - SEVERITY: HIGH]
Service: order-processor-7c6f8d...
Anomalie Détectée: Corrélation anormale entre la latence de la route /api/v2/order/validate et la consommation mémoire.
Prédiction: Crash du pod par OOMKilled probable dans ~75 minutes avec un niveau de confiance de 92%.
Cause Racine Suggérée: Fuite mémoire probable dans le `OrderValidatorService`.
Action Recommandée: Déclencher un redémarrage progressif du pod de manière préventive pour éviter une interruption de service.Tu vois la différence ? L'alerte n'est plus un simple "ça a cassé", mais un véritable plan d'action qui t'informe du quoi, du pourquoi et du comment agir, bien avant l'impact.
Les défis de l'intelligence artificielle en production
Bien que prometteuse, cette technologie n'est pas une solution miracle. L'adopter aveuglément sans comprendre ses contraintes mène souvent à la désillusion. Il est essentiel de garder un esprit critique et de comprendre les investissements nécessaires.
| Avantages Stratégiques | Coûts et Risques Associés |
|---|---|
| Réduction drastique du nombre d'incidents critiques. | Coût élevé des plateformes AIOps (licences et infrastructure). |
| Amélioration de la résilience opérationnelle et du SLO. | Nécessite des données de télémétrie de très haute qualité (coût d'instrumentation). |
| Libère du temps pour les équipes SRE qui passent moins de temps en astreinte. | Risque de "fatigue des alertes" due aux faux positifs si le modèle est mal entraîné. |
| Aide à l'identification de la dette technique et des bugs de performance. | Compétences pointues nécessaires en interne (Data Science, MLOps) pour maintenir et affiner les modèles. |
Le plus grand défi est souvent culturel. Les équipes doivent apprendre à faire confiance aux prédictions de la machine, tout en restant capables de les challenger. Cela demande de développer une nouvelle compétence : celle d'interpréter et de valider les recommandations de l'IA.
Conclusion : Vers des opérations autonomes
L'observabilité prédictive n'est pas une simple évolution, c'est une refonte de notre philosophie de la production. Nous passons d'un rôle de "pompiers" du numérique à celui "d'architectes" de systèmes résilients, capables de s'auto-diagnostiquer et, à terme, de s'auto-réparer.
Le chemin est encore long, et l'adoption de ces outils demande de la rigueur et un investissement significatif. Mais le gain est immense : des systèmes plus fiables, des nuits plus calmes et des ingénieurs focalisés sur la création de valeur plutôt que sur la gestion de crises. Prépare-toi, car le futur des opérations est déjà là, et il est prédictif.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
18 commentaires
La perfection n'existe pas. On a tous des bibliothèques tierces qui fuient. L'observabilité prédictive, c'est aussi un filet de sécurité pour quand le code n'est pas parfait, ce qui arrive tout le temps en production.
Et si on parlait de la dette technique ? Plutôt que de mettre une IA pour prédire un
OOMKilled, on ne devrait pas juste corriger la fuite mémoire dans le code ? C'est ça, le vrai DevOps.C'est un investissement, c'est sûr. Mais compare ça au coût d'une panne majeure de 2 heures en plein Black Friday. Le calcul de ROI est souvent positif si tu as une plateforme de taille conséquente.
Ça semble bien beau mais quid du coût cloud ? Entre le stockage des logs pour entraîner tes modèles et le calcul pour l'IA, tu vas exploser ton budget
AWSouGCPtrès vite.Exactement. Le seuil fixe devient vite une limite. Quand tu as des dépendances complexes, tu ne peux pas juste monitorer un service en silo. Voici un exemple de ce qu'on peut capturer avec les modèles :
Ouais, mais avec 500 microservices, tes alertes Prometheus finissent par être illisibles. Le besoin de corrélation est réel, même si la méthode prédictive est encore jeune.
Au final, est-ce que c'est pas juste du marketing pour justifier des coûts de licence énormes ? Un bon vieux
Prometheusavec des alertes basées sur des seuils, ça marche depuis 10 ans et c'est prévisible.Je suis d'accord, le mode 'auto-pilot' est risqué. Dans mon setup, l'action est toujours suggérée via une commande que l'ingénieur doit valider. On reste sur une assistance humaine, pas sur une délégation totale.
Tout à fait. La
auto-remediation, c'est le truc que tu désactives dès que tu mets le pied en prod. On veut des alertes intelligentes, pas un robot qui joue avec nosDeploymentKubernetes.L'idée de remédiation automatique me fait froid dans le dos. Si ton IA décide de redémarrer un pod en pleine charge parce qu'elle croit voir une fuite mémoire alors que c'est juste un pic de trafic légitime, tu viens de créer une panne toi-même.
C'est pour ça que je dis que la qualité est reine. Si tu n'as pas de
spancohérents, ne perds pas ton temps avec des modèles prédictifs. Il faut d'abord investir dans une instrumentation standardisée avant de vouloir faire du prédictif.Moi ce qui me fait peur, c'est la dépendance à la qualité des données. Si ton
OpenTelemetryest mal configuré sur un service, ton modèle causal devient complètement inutile, voire dangereux. On n'a pas tous le luxe d'avoir des traces parfaites partout.J'ai testé des solutions similaires. Le problème, c'est l'overhead CPU. Si tu ajoutes trop d'agents pour l'observabilité prédictive, tu finis par ralentir tes services alors que tu cherchais à les rendre plus résilients. C'est le serpent qui se mord la queue.
Point valide. On doit absolument passer par des
pipelinesde masquage de données avant l'ingestion dans le modèle. C'est une étape non négociable, surtout avec des logs applicatifs.Ton exemple avec
ops-ai-cli predict, c'est sympa, mais tu gères comment la sécurité des données qui partent dans ton moteur d'IA ? Si tu envoies des traces avec des headers HTTP potentiellement sensibles, tu te retrouves avec une fuite de données via ton outil d'observabilité.Je comprends le scepticisme. L'idée n'est pas de laisser l'IA décider seule, mais d'avoir un outil qui te donne une probabilité plutôt qu'une alerte binaire. Pour la maintenance, on utilise une approche par
sidecarpour collecter les métriques spécifiques au modèle, ce qui réduit la complexité de l'instrumentation.Exactement. Le coup du modèle causal qui prédit un OOMKilled 75 minutes avant, c'est joli sur le papier mais en prod avec du trafic variable, ton
baselineva bouger tous les quatre matins. Tu fais comment pour maintenir ton modèle sans une équipe de data scientists à plein temps ?Encore un article qui vend du rêve avec l'IA. Franchement, t'as déjà essayé de corréler des logs de 50 microservices en temps réel ? C'est le meilleur moyen de se bouffer des faux positifs à la pelle et de finir avec une fatigue d'alerte monumentale.