L'Infrastructure IA-Native : Le Cœur Intelligent du Cloud & DevOps
Vous avez passé des heures à peaufiner vos scripts Terraform et vos manifestes Kubernetes, pensant avoir atteint le summum de l'automatisation. Et si je vous disais que cette approche, si puissante soit-elle, n'est que la préhistoire de ce qui nous attend ? L'infrastructure ne se contente plus d'obéir à nos déclarations, elle commence à penser par elle-même.
Nous entrons dans une ère où les plateformes cloud et les orchestrateurs ne sont plus de simples exécutants, mais des partenaires cognitifs. L'infrastructure devient sensible au contexte, capable d'apprendre de ses propres métriques pour prendre des décisions autonomes et optimiser en continu les applications qu'elle héberge. C'est la promesse de l'Infrastructure IA-Native.
Décortiquons l'Infrastructure IA-Native
Oubliez l'image d'une intelligence artificielle comme une surcouche logicielle que l'on ajoute à un système existant. L'approche IA-Native consiste à infuser l'intelligence directement au cœur du système d'exploitation du cloud, des hyperviseurs jusqu'aux runtimes de conteneurs. L'IA n'est plus un outil, elle est le tissu même de l'infrastructure.
Fondamentalement, une Infrastructure IA-Native est un système qui utilise des modèles d'apprentissage machine pour gérer de manière proactive et autonome son propre état, sa performance, sa sécurité et son allocation de ressources. Elle ne se contente pas de réagir à des seuils prédéfinis dans un fichier de configuration, elle anticipe les besoins et les défaillances.
Du pilotage réactif au pilotage prédictif
L'automatisation traditionnelle, basée sur l'Infrastructure as Code (IaC), est fondamentalement réactive. Un pod tombe ? Kubernetes le redémarre. Un pic de CPU dépasse 80% ? L'autoscaler ajoute une instance. Ces actions sont des réponses à des événements déjà survenus. C'est efficace, mais cela implique toujours une latence, un micro-incident qui a dû se produire pour déclencher la remédiation.
L'intelligence native inverse cette logique. En analysant en permanence les flux de logs, les traces applicatives et les métriques système, elle construit un modèle prédictif du comportement normal de votre application. Elle peut ainsi détecter des anomalies subtiles, des signaux faibles qui précèdent une panne, et agir avant même que l'incident n'ait un impact visible pour l'utilisateur.
Les composantes d'un système cognitif
Pour atteindre ce niveau de proactivité, plusieurs briques logicielles intelligentes collaborent en permanence au sein de la plateforme. Chacune joue un rôle spécifique dans la gestion autonome du cycle de vie des applications et de l'infrastructure sous-jacente.
- Le Scheduler Cognitif : Il ne se contente plus de placer des conteneurs sur les nœuds les moins chargés. Il analyse les profils de consommation des workloads (CPU, mémoire, I/O réseau) et anticipe leurs besoins futurs pour les placer sur les nœuds les plus adéquats, en optimisant à la fois la performance et les coûts énergétiques.
- Le Moteur de Sécurité Prédictive : Au lieu de se baser uniquement sur des signatures de vulnérabilités connues (CVE), ce moteur analyse les comportements anormaux au niveau des appels système et du trafic réseau. Il peut ainsi isoler un conteneur au comportement suspect avant même qu'une attaque ne soit formellement identifiée.
- L'Optimiseur de Ressources Continu : Cette brique ajuste en temps réel et de manière fine les requêtes et limites de CPU/mémoire allouées à chaque application, en se basant sur sa consommation réelle observée sur plusieurs semaines. Fini le gaspillage de ressources ou le "throttling" inattendu.
L'impact direct sur nos métiers de DevOps
Cette évolution fondamentale de l'infrastructure transforme radicalement notre quotidien. Elle ne vise pas à nous remplacer, mais à augmenter nos capacités en nous libérant des tâches à faible valeur ajoutée pour nous concentrer sur l'architecture et l'innovation applicative. Le DevOps devient moins un pompier et plus un architecte de systèmes résilients.
Une CI/CD qui apprend de ses erreurs
Imaginez un pipeline de CI/CD (Intégration et Déploiement Continus) qui ne se contente plus d'exécuter une suite de tests statiques. Dans un monde IA-Native, le pipeline analyse l'impact de chaque nouvelle livraison sur la performance et la stabilité de l'environnement de production.
Si un déploiement, même après avoir passé tous les tests fonctionnels, entraîne une dégradation subtile du temps de réponse ou une augmentation de la consommation mémoire, le système peut automatiquement initier un rollback partiel ou alerter l'équipe de développement avec un contexte précis. Le pipeline devient une boucle de rétroaction intelligente.
# pipeline-intelligent.yml
# Ce n'est plus une simple séquence de commandes,
# mais une déclaration d'intention avec des objectifs de performance.
apiVersion: smart-ci.io/v1
kind: SmartPipeline
metadata:
name: api-gateway-pipeline
spec:
source:
git: git@github.com:my-org/api-gateway.git
stages:
- name: build
uses: kaniko-builder
- name: deploy
strategy:
type: CanaryIA
# L'IA va gérer le déploiement progressif
# en observant les indicateurs de santé (SLO)
target SLOs:
- metric: latency_p99_ms
threshold: 50
- metric: error_rate_percent
threshold: 0.1
# Si les SLOs sont dégradés, l'IA déclenche un rollback
# et annote le commit avec la cause probable de la régression.
onFailure:
action: autoRollback
notify:
channel: {{ git.author.slack }}
message: "Le déploiement du commit {{ git.commit.sha }} a été annulé car il dégradait la latence p99."L'Observabilité Augmentée : voir avant que ça ne casse
L'Observabilité Augmentée est le passage d'une surveillance passive à une compréhension active du système. Les plateformes IA-Natives ne se contentent pas de collecter des téraoctets de logs, de métriques et de traces elles les corrèlent en temps réel pour en extraire du sens et des recommandations.
Plutôt que de vous noyer sous des milliers d'alertes, le système vous présente une poignée d'incidents contextualisés, en identifiant la cause racine probable et en suggérant des actions de remédiation. C'est la fin de la fatigue d'alerte et le début du dépannage assisté par IA.
| Approche Traditionnelle | Approche IA-Native (Observabilité Augmentée) |
|---|---|
| Alerting basé sur des seuils statiques (CPU > 90%). | Détection d'anomalies basée sur le comportement appris. |
| Silos de données : logs, métriques, traces séparés. | Corrélation automatique des signaux pour identifier la cause racine. |
| Dashboards manuels à interpréter. | Génération de résumés d'incidents en langage naturel. |
| Recherche manuelle dans les logs ("grep de l'enfer"). | Suggestions proactives de remédiation basées sur des incidents passés. |
[Le rôle de l'ingénieur évolue]
Votre expertise n'est plus dans le réglage fin des seuils d'alerte, mais dans l'apprentissage du modèle. Vous entraînez l'IA à comprendre ce qui est "normal" pour votre application, en validant ou en invalidant ses suggestions pour affiner sa précision au fil du temps.
L'architecture cognitive en action
Pour mieux visualiser comment ces composants interagissent, imaginons un flux de gestion d'incident dans une telle infrastructure. Le processus n'est plus linéaire, mais forme une boucle de rétroaction continue, où chaque événement enrichit la connaissance globale du système.
Ce schéma illustre comment un comportement applicatif anormal est détecté, analysé et corrigé de manière autonome, transformant l'infrastructure en un système de défense immunitaire pour vos applications.
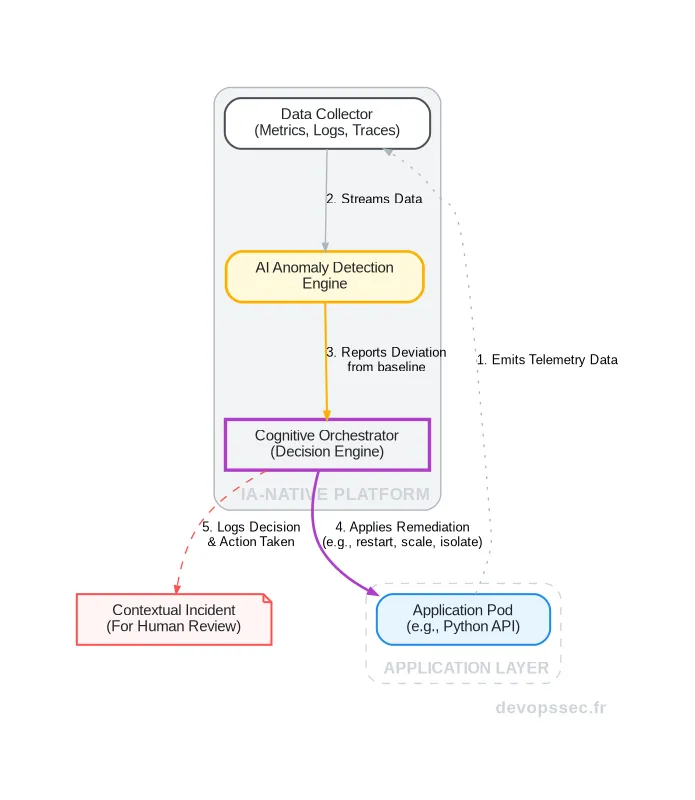
Dans ce flux, l'agent d'observabilité collecte en permanence les données de l'application. Le moteur de détection d'anomalies, entraîné sur le comportement historique, identifie une déviation subtile. Au lieu de simplement déclencher une alerte, il transmet cette anomalie contextualisée à l'Orchestration cognitive, qui prend alors la décision la plus appropriée, comme redémarrer le pod, avant même qu'un humain n'ait eu le temps de lire la notification.
Conclusion : Adopter une nouvelle mentalité
L'avènement de l'infrastructure IA-Native ne représente pas seulement un changement technologique, mais un véritable changement de paradigme pour les équipes DevOps. Il nous invite à passer du rôle d'opérateur à celui de superviseur de systèmes intelligents. Notre mission n'est plus de coder des règles, mais d'enseigner des stratégies.
Cette transition ne se fera pas en un jour. Elle exige de nouvelles compétences en analyse de données et en machine learning, ainsi qu'une confiance mesurée dans les décisions de l'IA. Mais le gain potentiel est immense : des systèmes plus résilients, plus performants et plus sécurisés, qui nous permettent enfin de nous concentrer sur ce qui compte vraiment, la valeur métier de nos applications.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
20 commentaires
Le overhead est marginal par rapport au gaspillage que vous avez aujourd'hui avec des sur-provisionnements constants. On parle d'efficacité globale ici.
Ok, admettons. Mais quel est le coût en CPU/RAM pour faire tourner ces modèles dans le cluster ? Si je perds 15% de mes ressources pour monitorer les 85% restants, c'est absurde.
C'est justement le point. L'optimiseur de ressources continu fait ce boulot de
requests/limitsautomatiquement et bien mieux que n'importe quel humain qui ajuste ça une fois par semestre.La tech est intéressante, mais le timing est mauvais. La majorité des boîtes n'arrivent même pas à gérer correctement leurs
resources requests. Commencez par là avant de parler IA.98% de confiance ? Et les 2% restants qui foutent tout en l'air ? Non merci. Je garde mes seuils statiques, au moins je sais pourquoi ça alerte.
On ne demande pas de faire confiance aveuglément. L'IA doit justifier ses choix. Si elle propose un rollback, elle doit fournir le contexte :
D'accord avec le 9. Plus ton système est "intelligent", plus il est opaque. Quand ça plante, tu passes 3 jours à comprendre pourquoi l'IA a pris cette décision. C'est l'enfer du troubleshooting.
Le souci c'est la complexité ajoutée au stack. Déjà qu'on galère avec les
CRDcustom et les opérateurs, rajouter une couche d'IA, c'est rajouter des points de panne.Vous voyez ça comme une menace, je le vois comme un assistant. Personne ne vous force à l'auto-remédiation totale au début. On peut commencer par de l'aide au diagnostic.
Le risque majeur c'est la fatigue d'alerte déplacée. Si l'IA commence à proposer des remédiations, on va juste valider sans réfléchir. C'est le piège de l'automatisation.
"L'infrastructure devient sensible au contexte". C'est marketing tout ça. En attendant, quand mon
etcdest corrompu, aucune IA ne va me le réparer. Je préfère un bon vieuxetcdctl snapshot restore.C'est là que l'observabilité augmentée intervient. Elle trie le bruit. Le but est justement de ne plus faire de
grepmanuel dans des logs pollués par des erreurs non critiques.Surtout que pour entraîner ces modèles, il faut des téraoctets de données propres. Qui ici a des logs assez propres pour que l'IA ne délire pas complètement ?
Le
CanaryIA, c'est mignon, mais en prod, si ça rollback pendant un pic de trafic parce que la latence a pris 5ms de plus à cause d'un bruit réseau, tu crées une instabilité majeure. Le déterminisme est une vertu, pas un défaut.La source de vérité reste le manifeste. L'IA agit comme un contrôleur qui ajuste les paramètres à chaud, tout comme le fait déjà le
kube-scheduler, mais de façon plus granulaire. Regardez comment on peut structurer un feedback loop :C'est clair. On a mis des années à stabiliser nos pipelines avec
terraform planetkubectl apply. Là, vous proposez de réintroduire de l'entropie sous couvert d'intelligence.Le problème c'est la boîte noire. Si mon
deployment.yamlest modifié en douce par une IA, comment je garantis l'état de mon infra ? L'IaC perd tout son sens si l'état réel diverge constamment de la source de vérité.L'idée n'est pas de supprimer le contrôle, mais d'ajouter une couche d'observabilité. Le
Scheduler Cognitifne fait pas n'importe quoi, il est contraint par tes SLOs. C'est l'évolution logique duHorizontalPodAutoscaleractuel.Exactement. J'ai déjà assez de mal à expliquer à mes devs pourquoi le
hpascale pas quand ils ont oublié de définir desresources.limits. Si en plus une IA décide de faire du shuffling de nœuds, c'est la porte ouverte aux effets de bord imprévisibles.Encore un article qui vend du rêve avec des buzzwords. L'infrastructure qui "pense" par elle-même, c'est juste un enfer à débugger. Quand ton cluster décide tout seul de bouger tes pods basés sur une "analyse prédictive" foireuse, tu fais quoi ?