L'Illusion du Tout-En-Un Face au Mur de la Réalité
Héberger des bases de données critiques au sein même d'un cluster d'orchestration de conteneurs est le débat le plus sanglant de l'ingénierie moderne. Sur le papier, l'idée est séduisante car elle promet de gérer toute l'infrastructure via un seul et unique outil, simplifiant théoriquement le travail des équipes de déploiement. Cependant, la réalité du terrain se heurte souvent violemment aux lois de la physique réseau et à la nature profondément éphémère des conteneurs.
L'orchestrateur a été conçu historiquement pour tuer et recréer des processus à la volée, sans aucun état d'âme. Or, une base de données relationnelle est l'exact opposé : c'est un coffre-fort lourd, lent à démarrer, qui exige de la stabilité et une connexion constante à ses disques durs. Tenter de marier ces deux philosophies nécessite l'usage des StatefulSets, des composants spécifiques qui tentent d'attacher un identifiant fixe et un disque persistant à un conteneur volant.
Le problème majeur réside dans la couche d'abstraction du stockage réseau, qui agit comme un tuyau virtuel entre votre serveur de calcul et vos disques physiques. Lorsque l'orchestrateur décide de déplacer brutalement votre base de données d'une machine physique à une autre suite à une saturation mémoire, ce fameux tuyau doit être débranché puis rebranché ailleurs. Pendant ces quelques secondes d'incertitude, votre application entière se retrouve paralysée, incapable d'écrire la moindre ligne de commande client.
Les Promesses Brisées de l'Automatisation
Pour pallier ces faiblesses architecturales, la communauté a créé les Opérateurs Kubernetes. Imaginez ces opérateurs comme de petits robots logiciels embarqués dont le seul but est de surveiller et réparer votre base de données en temps réel. Ils automatisent les tâches complexes comme la création de sauvegardes, l'ajout de nouveaux nœuds de lecture ou le basculement d'urgence en cas de crash du nœud principal.
Malgré la sophistication de ces robots, ils restent tributaires des composants sous-jacents de votre fournisseur cloud. Voici à quoi ressemble la déclaration d'un cluster de base de données haute disponibilité prêt pour la production via un opérateur moderne. Observez la complexité des règles d'affinité nécessaires pour empêcher le système de placer tous les œufs dans le même panier.
apiVersion: "acid.zalan.do/v1"
kind: postgresql
metadata:
name: prod-database-cluster
namespace: data-tier
spec:
teamId: "backend-ops"
volume:
size: 500Gi
storageClass: "premium-rwo"
numberOfInstances: 3
users:
api_user:
- superuser
- createdb
enableMasterLoadBalancer: false
enableReplicaLoadBalancer: true
resources:
requests:
cpu: "4"
memory: "16Gi"
limits:
cpu: "8"
memory: "32Gi"
postgresql:
version: "15"
parameters:
shared_buffers: "8GB"
max_connections: "500"
work_mem: "32MB"
tolerations:
- key: "dedicated"
operator: "Equal"
value: "database"
effect: "NoSchedule"
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "topology.kubernetes.io/zone"
operator: "In"
values:
- "eu-west-1a"
- "eu-west-1b"
- "eu-west-1c"L'importance de l'isolation matérielle
Dans l'exemple ci-dessus, remarquez l'utilisation des tolérances et de l'affinité de nœud. Ne mélangez jamais vos charges de travail volatiles (comme un serveur web) sur les mêmes machines physiques que vos bases de données. Une fuite mémoire sur une application mal codée pourrait étouffer votre base de données et provoquer un crash généralisé.
Ce code illustre la nécessité de forcer l'orchestrateur à répartir les instances sur différentes zones géographiques. Si vous omettez ces règles strictes, l'algorithme de placement par défaut pourrait très bien démarrer vos trois instances de base de données sur le même serveur physique. En cas de panne matérielle de ce serveur précis, votre haute disponibilité s'effondrerait instantanément, détruisant tout espoir de récupération rapide.
Anatomie d'un Désastre Annoncé
La théorie est rassurante, mais laissez-moi vous raconter une nuit d'astreinte qui a forgé mes convictions. Nous gérions une plateforme e-commerce générant des milliers de transactions par minute, entièrement hébergée sur un cluster unifié. Vers deux heures du matin, une simple micro-coupure réseau entre deux zones de disponibilité a déclenché une réaction en chaîne catastrophique au niveau de notre base de données embarquée.
La coupure a isolé le nœud principal de ses réplicas pendant à peine quinze secondes. C'est le fameux scénario du Split-Brain, une situation absurde où la communication est coupée et où deux serveurs se proclament simultanément chefs légitimes. L'opérateur interne, paniqué par la perte de communication, a automatiquement promu un réplica en tant que nouveau maître, tandis que l'ancien maître, toujours en vie mais sourd, continuait d'accepter des écritures locales.
Lorsque le réseau est revenu à la normale, nous nous sommes retrouvés avec deux historiques de données divergents et totalement incompatibles. Aucun outil automatisé ne peut fusionner par magie des transactions financières qui se contredisent. Ce qui aurait dû être une simple alerte de latence s'est transformé en une corruption d'état nécessitant sept heures d'intervention manuelle à haut risque.
Le Piège du Basculement Automatique

Examinons les traces concrètes de cet incident pour comprendre la mécanique de la défaillance. Vous verrez comment le système de surveillance des nœuds a mal interprété une latence temporaire comme une mort définitive de l'instance. C'est l'illustration parfaite du danger de déléguer des décisions d'état critiques à des algorithmes conçus pour des charges volatiles.
# Extraction des événements Kubernetes liés au Pod Master
kubectl get events -n data-tier --field-selector involvedObject.name=prod-database-cluster-0Résultat:
LAST SEEN TYPE REASON MESSAGE
14m Warning Unhealthy Readiness probe failed: timeout 5s
14m Warning NodeNotReady Node worker-zone-a is unresponsive
13m Normal LeaderElection Lost leader lease. Pod prod-database-cluster-1 acquiring lock
13m Normal Promotion Pod prod-database-cluster-1 promoted to Master
12m Warning SplitBrainRisk Pod prod-database-cluster-0 reconnected but lock held by cluster-1
12m Warning DataDivergence Timeline ID mismatch detected! Manual intervention required.
12m Normal Killing Stopping container postgres to prevent further corruptionLa corruption par divergence
L'erreur fatale ici se lit dans la ligne indiquant un Timeline ID mismatch. Cela signifie que le système a dû s'amputer lui-même en tuant le conteneur d'origine pour éviter d'aggraver le problème. Si ce mécanisme de sécurité avait failli, les données de production auraient été irrémédiablement corrompues.
Cet incident souligne une vérité dérangeante : l'orchestration de conteneurs excelle dans l'auto-guérison des applications sans état, mais se révèle atrocement brutale lorsqu'il s'agit de résoudre des conflits de données. Les délais de grâce, les sondes de vitalité et les bascules automatiques doivent être configurés avec une précision chirurgicale, faute de quoi ils deviennent les propres fossoyeurs de votre infrastructure.
Le Choc des Architectures : K8s vs Managé
Face à ces risques majeurs, l'industrie s'est massivement tournée vers les services managés externes (comme RDS ou Cloud SQL). Le paradigme est simple : on laisse l'orchestrateur gérer la puissance de calcul volatile, et on confie les joyaux de la couronne à une infrastructure externe dédiée, conçue spécifiquement pour la durabilité de la donnée.
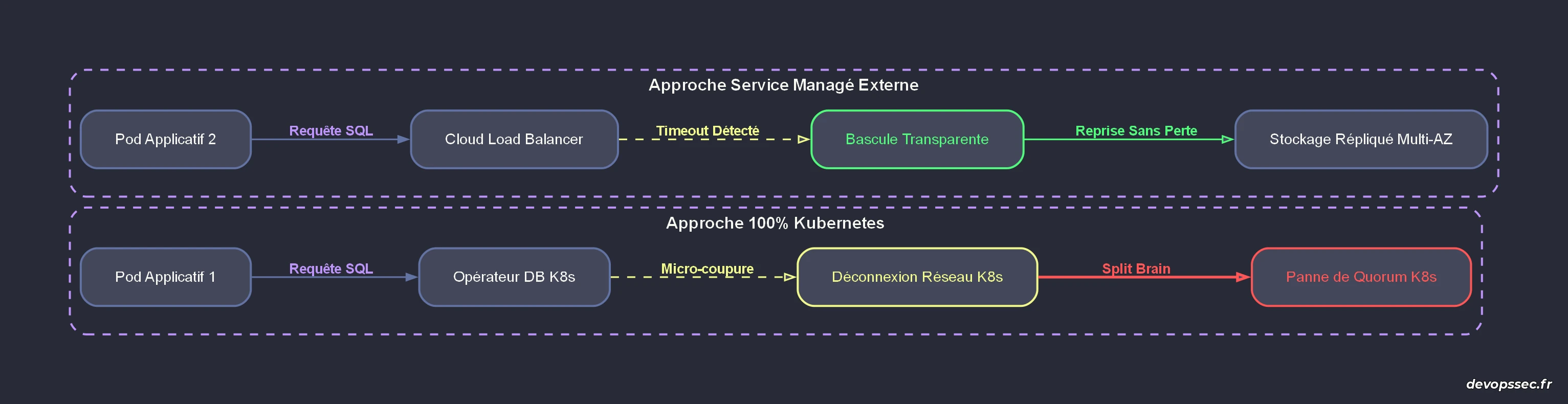
Le schéma ci-dessus met en évidence la différence cruciale de comportement lors d'une défaillance réseau. Dans l'approche purement conteneurisée, la micro-coupure remonte jusqu'à l'opérateur logiciel qui, soumis aux mêmes contraintes réseau que le reste du cluster, perd son quorum et déclenche un échec critique. À l'inverse, l'approche externe délègue cette responsabilité à une couche matérielle et réseau sous-jacente infiniment plus robuste, garantissant une bascule de l'adresse IP vers un nœud de secours de manière quasi invisible pour le code applicatif.
La Vraie Métrique du Coût Total de Possession
Les partisans du "Tout-Kubernetes" brandissent souvent l'argument financier pour justifier leur choix. Ils calculent le coût brut des machines virtuelles et démontrent qu'il est moins cher de louer des serveurs standards pour y faire tourner sa propre base de données plutôt que de payer la surtaxe des services managés. C'est une vision naïve qui ignore totalement le coût humain de la maintenance.
| Critère Opérationnel | Base de Données dans Kubernetes | Service Managé Externe (ex: RDS) |
|---|---|---|
| Mise à jour de version majeure | Risquée. Nécessite des tests approfondis de l'opérateur et des migrations manuelles des volumes. | Un simple clic. Le fournisseur gère la prise de snapshot et le basculement. |
| Gestion des sauvegardes | À scripter via des CronJobs et des outils externes. Nécessite de vérifier les restaurations. | Automatique et continue (Point-in-time recovery). Rétention gérée contractuellement. |
| Temps humain mobilisé | Élevé. Exige des ingénieurs pointus maîtrisant à la fois le stockage K8s et l'administration de bases de données. | Faible. L'équipe se concentre sur l'optimisation des requêtes applicatives. |
| Récupération après sinistre (DR) | Complexe. Exige de reconstruire les volumes persistants et les liens symboliques. | Garantie par les accords de niveau de service (SLA) du fournisseur cloud. |
Ce tableau comparatif démontre que les économies d'infrastructure réalisées en hébergeant soi-même sa donnée sont immédiatement pulvérisées par le coût des salaires des experts requis pour maintenir le système à flot. Lorsqu'une base de données managée tombe en panne, c'est le problème de votre fournisseur cloud, et il a des armées d'ingénieurs sur le pont. Lorsque votre propre opérateur s'effondre à trois heures du matin, vous êtes tragiquement seul face à vos lignes de commandes.
L'illusion du contrôle total masque souvent une dette technique massive. Demandez-vous si la valeur ajoutée de votre entreprise réside dans sa capacité à opérer laborieusement des clusters de bases de données, ou dans le développement de fonctionnalités pour vos utilisateurs. Pour 95% des entreprises, la réponse dicte d'externaliser la persistance critique.
Les Exceptions qui Confirment la Règle
Doit-on pour autant bannir définitivement tout état persistant de nos clusters d'orchestration ? En tant qu'ingénieur pragmatique, je vous dirais que la réponse est non. Il existe des cas d'usage précis où l'hébergement interne fait parfaitement sens, à condition de comprendre la nature de la donnée que vous manipulez. La règle d'or est simple : si la perte totale du cluster ne met pas la clé sous la porte de votre entreprise, alors vous pouvez tenter l'expérience.
Les environnements de test et les pipelines d'intégration continue sont d'excellents candidats. Pouvoir déployer automatiquement une base de données vierge, exécuter une batterie de tests, puis détruire l'ensemble de l'environnement en fin de cycle est une victoire écrasante pour la productivité des développeurs. Dans ce contexte, l'éphémère est une fonctionnalité, pas un risque.
L'Éphémère et le Distribué par Design
Certains systèmes de stockage modernes ont été conçus dès le premier jour pour survivre dans des environnements hostiles et chaotiques. Contrairement aux bases de données relationnelles traditionnelles, ces outils embrassent la philosophie de la perte de nœuds comme un fonctionnement nominal. Voici les candidats qui tolèrent particulièrement bien la conteneurisation :
- Les systèmes de cache (Redis, Memcached) : Leur but est d'accélérer la lecture en stockant la donnée en mémoire vive. Si un conteneur plante, la donnée est perdue, mais l'application principale ira simplement la recharger depuis la vraie base de données externe.
- Les files de messages distribuées (Apache Kafka) : L'architecture de Kafka réplique massivement de petits segments de données sur plusieurs nœuds. Il est nativement conçu pour détecter les pannes de conteneurs et rééquilibrer ses partitions de manière autonome.
- Les moteurs de recherche orientés documents (Elasticsearch) : Similaires à Kafka, ils gèrent leur propre système de fragmentation et de réplication. Un opérateur peut très efficacement ajouter ou retirer des nœuds au cluster sans interruption de service.
Le point commun de ces technologies est leur Agnosticisme Matériel. Elles n'ont pas besoin d'un lien fusionnel avec un disque dur ultra-performant spécifique. Elles tirent leur résilience de leur capacité à s'éparpiller en réseau et à se reconstruire à la volée. C'est ici que la puissance de l'orchestrateur de conteneurs s'exprime pleinement, en fournissant l'élasticité nécessaire pour absorber des pics de charge massifs.
Cependant, même pour ces technologies plus adaptées, la vigilance reste de mise concernant les performances d'entrées et sorties (I/O) du disque. Si vous déployez une base de données distribuée lourde, veillez à utiliser un stockage local NVMe attaché directement aux nœuds physiques, plutôt que de passer par un stockage en réseau lent et sujet aux goulots d'étranglement.
# Exemple d'utilisation d'un volume local pour des performances maximales
apiVersion: v1
kind: PersistentVolume
metadata:
name: local-nvme-pv-1
spec:
capacity:
storage: 1Ti
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-storage
local:
path: /mnt/disks/nvme0n1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- worker-node-performance-1L'utilisation d'un volume local, comme illustré dans ce manifeste avec le paramètre /mnt/disks/nvme0n1, permet de contourner la latence du stockage réseau. Mais attention, cela crée un couplage fort avec le serveur worker-node-performance-1. Si ce serveur physique brûle, les données du disque partent en fumée avec lui. Vous comptez alors entièrement sur la réplication applicative (au niveau de Kafka ou Elasticsearch) pour garantir votre survie.
Le Verdict du Déploiement
Héberger des données critiques sur un orchestrateur de conteneurs n'est plus techniquement impossible, mais cela reste une prise de risque que la majorité des équipes sous-estiment lourdement. Les opérateurs ont certes comblé le fossé opérationnel, mais ils ne peuvent pas corriger la nature volatile de l'infrastructure sous-jacente. Il ne s'agit pas de savoir si l'outil en est capable, mais si votre équipe possède la maturité et les ressources nécessaires pour gérer les crises inévitables qui en découleront.
Mon conseil pour les jeunes architectes est tranché : commencez toujours par extraire votre état critique vers des services managés par votre fournisseur cloud. Concentrez la puissance de vos clusters sur le calcul pur, le déploiement continu et la logique métier de votre application. Ne franchissez le Rubicon du stockage conteneurisé que lorsque les factures de votre base de données managée deviennent l'obstacle numéro un à la croissance de votre entreprise.
La beauté de l'ingénierie DevOps ne réside pas dans l'utilisation de l'outil le plus complexe possible pour impressionner ses pairs, mais dans la sélection de l'outil le plus ennuyeux et prévisible possible pour garantir le sommeil de l'équipe d'astreinte. La donnée de vos utilisateurs est la chose la plus précieuse que vous gérez ; traitez-la avec le respect architectural qu'elle mérite.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
16 commentaires
Exactement. La valeur n'est pas dans le serveur, elle est dans le SLA de restauration.
Quand le téléphone sonne à 3h du matin pour une corruption de données, tu te fous de savoir si ton infra est "cloud native" ou non.
Le débat est clos dès qu'on parle de disaster recovery. Restaurer un backup de 500Go depuis un volume K8s, c'est une plaie.
Dans le managé, tu as le point-in-time recovery en 3 clics.
Si tu veux pas payer RDS, utilise une VM classique, installe Postgres proprement avec
ansibleet fais tes sauvegardes sur S3.C'est moins "sexy" que K8s, mais c'est 100 fois plus prévisible.
Tu conseilles quoi pour une petite boîte qui veut pas payer le prix fort de RDS ?
Un cluster basique avec réplication asynchrone suffit souvent.
Kafka est conçu pour le chaos. Il réplique les données par design. C'est très différent d'une base Postgres qui nécessite une intégrité transactionnelle stricte sur un disque unique.
Si un nœud Kafka tombe, le cluster continue. Si ton master Postgres tombe, tu as un moment de flottement critique.
Quid de Kafka alors ? Tu dis que c'est une exception.
On a Kafka sur K8s et ça tourne très bien. L'opérateur Strimzi fait un boulot monstre.
Merci. C'est ça le point crucial. À quel moment le risque opérationnel dépasse le gain d'agilité ?
Pour 95% des boîtes, la réponse est simple : ne vous emmerdez pas, laissez le cloud provider gérer le cauchemar des sauvegardes.
D'accord avec l'auteur. J'ai vu des équipes perdre 48h de transactions sur une erreur de
PersistentVolumeClaimmal configuré.Le managé, c'est de l'assurance vie pour ton business.
Ce qui me fait rire, c'est les dev qui veulent du "Tout-K8s" juste pour pouvoir utiliser
helm installsur leur base de données.La simplicité du déploiement ne compense jamais l'instabilité de la donnée.
C'est une solution performante, mais très dangereuse. Regarde ce que ça implique pour la résilience :
Si ton nœud meurt, ton volume est indisponible. Tu transfères la complexité sur l'application qui doit gérer la réplication. C'est pas pour tout le monde.
Et le stockage local alors ? Tu en parles à la fin. Avec des NVMe, tu enlèves la latence réseau.
C'est pas ça la vraie solution pour du K8s performant ?
C'est le coût caché dont je parle. Le temps passé à migrer ton opérateur vaut largement le prix d'un service managé sur une année entière.
On oublie souvent que le salaire d'un ingénieur capable de débugger ces trucs coûte 10 fois plus cher que la facture cloud.
J'ai utilisé l'opérateur Zalando cité dans ton texte. Ça marche bien sur le papier, mais dès que tu veux faire un
pg_upgradede version majeure, c'est l'enfer.Tu te retrouves à bidouiller les manifests pendant des heures pour éviter que le cluster ne se recrée de zéro.
C'est exactement ce que je disais : l'illusion du contrôle. La configuration parfaite est un mythe en environnement distribué.
Quand tu as une micro-coupure réseau, aucun réglage ne sauvera ton quorum si l'infrastructure sous-jacente est instable.
Le problème, c'est pas l'outil, c'est l'ignorance des ops. Si tu sais gérer ton
storageClasset tes limites de ressources, K8s tient la route.Tu parles de Split-Brain, mais c'est une erreur de config, pas une fatalité de l'orchestrateur.
Franchement, ton article est courageux. On a tous essayé de jouer aux apprentis sorciers avec des StatefulSets pour économiser quelques euros sur RDS.
Le résultat ? Des
kubectl get podsen boucle de crash et des réveils à 3h du matin pour réparer un quorum corrompu. C'est du suicide industriel.