L'aube d'une nouvelle ère pour les microservices
Vous avez probablement déjà passé une nuit blanche à cause d'une alerte PagerDuty, déclenchée par un service critique qui s'effondre sans crier gare. Cette situation, emblématique de nos architectures distribuées, révèle une vérité fondamentale : nos systèmes sont devenus incroyablement complexes, mais leur capacité à gérer cette complexité est restée largement manuelle et réactive.
Pourtant, une transformation silencieuse est en cours. Nous passons de la simple orchestration, où Kubernetes redémarre un pod défaillant, à une véritable autonomie, où les services eux-mêmes deviennent des entités intelligentes, capables de se diagnostiquer, de se réparer et même de s'optimiser sans intervention humaine. Bienvenue dans l'ère des microservices autonomes.
Il ne s'agit plus seulement de résilience, mais d'antifragilité. L'objectif n'est plus de survivre à une panne, mais d'en sortir plus fort, en apprenant de chaque incident pour éviter qu'il ne se reproduise. C'est un changement de paradigme complet pour le DevOps.
Les piliers de l'intelligence système
Pour qu'un système devienne autonome, il doit reposer sur des fondations bien plus sophistiquées que les health checks traditionnels. L'autonomie n'est pas une fonctionnalité que l'on active, mais une capacité émergente issue de la synergie de trois piliers fondamentaux.
L'auto-diagnostic : Voir au-delà du symptôme
Un service qui répond avec un code HTTP 200 n'est pas nécessairement en bonne santé. Il peut être lent, consommer une quantité anormale de mémoire, ou avoir une dépendance qui est sur le point de flancher. L'auto-diagnostic consiste pour un service à avoir une conscience profonde de son état interne et de son environnement.
Cette conscience est alimentée par une observabilité de nouvelle génération. On ne se contente plus de collecter des métriques, des logs et des traces de manière passive. On utilise des technologies comme eBPF (Extended Berkeley Packet Filter) pour sonder le comportement du système au niveau du noyau Linux, sans aucune modification du code applicatif.
Cela permet de capturer des signaux de faible intensité, comme une augmentation subtile de la latence réseau ou une contention sur un verrou système, qui sont souvent les précurseurs d'une défaillance majeure. Le système ne se contente pas de savoir qu'il est "malade", il peut identifier précisément la nature de sa pathologie.
L'auto-réparation : L'action corrective intelligente
Une fois le diagnostic posé, le système doit pouvoir agir. L'auto-réparation va bien au-delà du simple redémarrage d'un conteneur. Il s'agit d'un catalogue d'actions contextuelles que le système peut déclencher de manière autonome pour restaurer son état nominal.
Concrètement, ces actions peuvent être très variées et dépendent de la nature du problème identifié. L'intelligence du système réside dans sa capacité à choisir la bonne action au bon moment, en se basant sur les données de l'observabilité et des politiques prédéfinies.
| Symptôme Détecté | Action d'Auto-Réparation Classique | Action d'Auto-Réparation Autonome |
|---|---|---|
| Latence élevée sur une dépendance | Alerte manuelle, ouverture d'un circuit breaker | Déclenchement d'un Circuit Breaker Adaptatif qui déroute le trafic vers un fallback, tout en envoyant des sondes pour détecter la récupération. |
| Fuite de mémoire lente | Redémarrage programmé hors heures de pointe | Déclenchement d'un "canary draining" : une nouvelle instance saine est démarrée, le trafic y est progressivement basculé, puis l'instance défaillante est arrêtée pour analyse. |
| Cache empoisonné (données invalides) | Purge manuelle du cache via une commande | Détection de la source des données invalides via le traçage distribué, purge ciblée de la clé corrompue et mise en quarantaine temporaire de la source de données. |
L'auto-optimisation : Apprendre du passé pour bâtir le futur
C'est le stade ultime de l'autonomie. Le système ne se contente pas de réparer les pannes, il apprend de chaque événement pour améliorer ses performances et sa résilience. Il ajuste ses propres paramètres pour éviter que les problèmes ne se reproduisent.
Par exemple, s'il détecte régulièrement une congestion sur un pool de connexions à la base de données chaque matin à 9h, il peut décider de manière proactive d'augmenter la taille de ce pool à 8h55, puis de la réduire à 10h pour économiser les ressources. Il modifie son propre comportement en fonction des schémas observés.
Cette boucle de rétroaction continue transforme une architecture réactive en un système vivant, qui s'adapte en permanence à son environnement et à sa charge de travail. C'est la promesse de l'AIOps (AI for IT Operations) appliquée au cœur même de l'architecture logicielle.
Architecture d'un système Self-Healing
Mettre en place un tel système n'est pas trivial. Cela requiert un couplage fort entre des outils d'observabilité avancés, un plan de contrôle intelligent (souvent un opérateur Kubernetes sur-mesure) et des applications conçues pour être pilotées de l'extérieur.
Le flux d'une action d'auto-réparation illustre bien cette orchestration complexe. Tout commence par la collecte passive de données à très haute granularité, qui est ensuite analysée en temps réel pour détecter des déviations par rapport à un comportement normal.
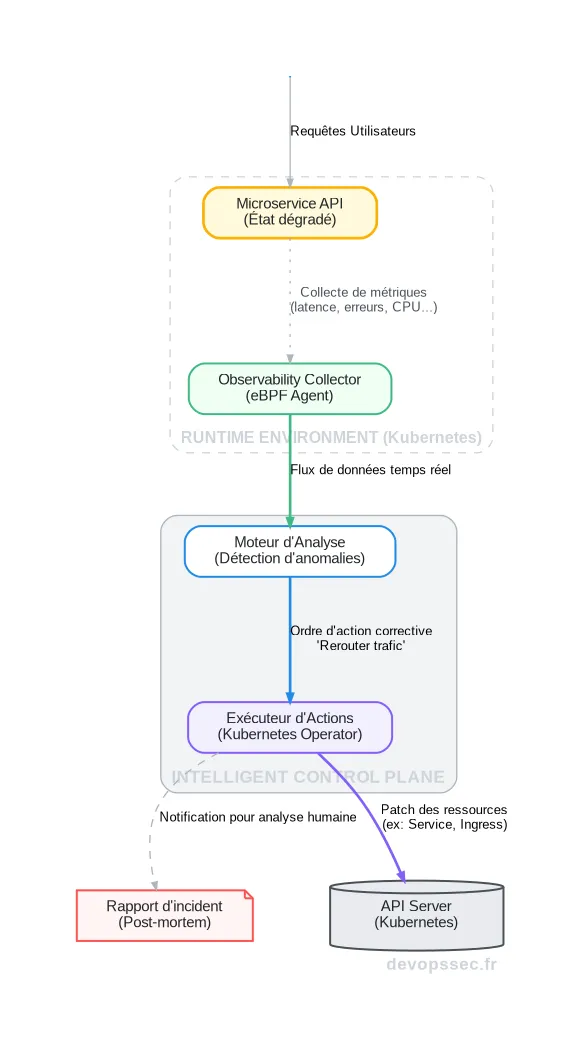
Le plan de contrôle, qui est le cerveau du système, doit être capable de corréler des signaux provenant de différentes sources pour prendre une décision éclairée. Par exemple, une simple augmentation de la latence n'est pas suffisante. Mais si elle est corrélée à une augmentation des erreurs 503 sur un service en aval et à une pression mémoire sur le pod, l'opérateur peut conclure avec une haute probabilité qu'un redémarrage ciblé est la solution la plus appropriée.
Voici à quoi pourrait ressembler une politique de self-healing, définie via une ressource personnalisée (CRD) dans Kubernetes. Notez comment elle lie un symptôme (un slo) à une série d'actions pondérées.
apiVersion: healing.acme.io/v1alpha1
kind: HealingPolicy
metadata:
name: user-service-latency-policy
spec:
# Cible le déploiement 'user-service'
targetRef:
kind: Deployment
name: user-service
# La condition qui déclenche la politique
trigger:
type: slo
slo:
# Si la latence au 99ème percentile dépasse 500ms pendant 2 minutes
metric: histogram_quantile(0.99, rate(http_requests_latency_seconds_bucket[5m]))
threshold: 0.5 # 500ms
duration: 2m
# Liste des actions à tenter, dans l'ordre
actions:
- name: clear-cache
weight: 80 # Tentative à 80%
command: ["/bin/sh", "-c", "redis-cli flushall"]
cooldown: 5m
- name: rolling-restart
weight: 20 # Tentative à 20% si la première échoue
strategy: canary
maxUnavailable: 1
cooldown: 15mLes angles morts de l'autonomie
L'idée d'un système qui se gère tout seul est séduisante, mais elle n'est pas sans risques. L'autonomie introduit de nouvelles couches de complexité, et comme toute technologie puissante, elle doit être maîtrisée avec précaution.
Le risque de la "boîte noire"
Lorsqu'un système prend des centaines de décisions correctives par jour, comment un ingénieur peut-il comprendre l'état réel de la production ? Si une action autonome provoque une panne en cascade, le débogage peut devenir un cauchemar. Il est crucial que chaque action soit tracée, expliquée et corrélée à l'anomalie qui l'a déclenchée.
L'enjeu de l'"explainability" est central. Nous devons construire des systèmes dont les décisions ne sont pas seulement efficaces, mais aussi compréhensibles par les humains qui en ont la charge. Sans cela, nous risquons de perdre le contrôle et la confiance dans nos propres créations.
Le Dry-Run est votre meilleur ami
Avant de donner à un opérateur le pouvoir de modifier la production, faites-le tourner en mode "dry-run" pendant des semaines. Il analysera les métriques et annoncera les actions qu'il aurait prises. Cela vous permet de valider sa logique et d'ajuster ses seuils sans aucun risque, transformant les logs en un outil d'apprentissage inestimable.
Un changement culturel avant tout
Les systèmes self-healing ne vont pas remplacer les ingénieurs DevOps ou SRE. Au contraire, ils élèvent le niveau de compétence requis. Le travail n'est plus d'éteindre des incendies, mais de devenir l'architecte, le formateur et le gardien de ces systèmes autonomes.
Les compétences requises évoluent : il faut non seulement maîtriser l'infrastructure et le code, mais aussi comprendre l'analyse de données, les modèles statistiques de détection d'anomalies et la théorie du contrôle. C'est un changement profond qui demande un investissement significatif en formation et en R&D.
Conclusion : Vers une infrastructure organique
Nous sommes au début d'un voyage passionnant. Les microservices autonomes représentent la prochaine évolution logique des systèmes distribués. En leur donnant les moyens de percevoir, de raisonner et d'agir, nous ne construisons plus des machines rigides, mais des organismes numériques capables de s'adapter et de survivre dans des environnements chaotiques.
Le rôle de l'ingénieur DevOps de demain ne sera plus celui d'un opérateur, mais celui d'un mentor pour une intelligence artificielle distribuée. Notre mission n'est plus de maintenir les systèmes en vie, mais de leur apprendre à vivre par eux-mêmes. C'est un défi immense, mais la promesse d'une infrastructure véritablement résiliente en vaut la peine.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
20 commentaires
On utilise une dashboard Grafana qui affiche les logs de l'opérateur avec un timestamp, le symptôme détecté et l'action corrélée.
Le secret, c'est de loguer chaque décision comme un événement Kubernetes standard, c'est comme ça qu'on garde une trace propre de tout ce qui se passe en prod.
Merci pour l'article. Pour l'
explainability, vous avez des outils de visualisation pour comprendre pourquoi une décision a été prise ?C'est pas du sur-mesure, c'est une
HealingPolicygénérique. Tu définis un pattern de charge et le contrôleur applique la règle à tous les services qui ont le même tag.Le but est de ne pas réinventer la roue pour chaque service.
L'auto-optimisation du pool de connexions à 8h55... c'est pas un peu du sur-mesure pour un cas d'usage précis ? Comment ça scale sur 500 microservices ?
On reste sur
etcdvia les Custom Resources. C'est l'avantage de Kubernetes : toute la logique d'état est native. Pas besoin de rajouter une couche de complexité avec une DB externe.Vous utilisez quoi pour stocker les états du plan de contrôle ?
etcdnatif ou une autre DB ?D'où l'importance de limiter le
maxUnavailableet d'utiliser descooldownstricts. Si le système redémarre en boucle, c'est qu'il y a un problème de fond que l'auto-réparation ne peut pas résoudre.Le système doit savoir dire "stop" et lever une alerte critique à l'humain.
Franchement, le
rolling-restarten mode automatique, c'est dangereux si t'as pas un monitoring parfait derrière. Une boucle infinie est vite arrivée.On corrèle le taux d'erreur 5xx avec les logs applicatifs. Si le cache renvoie des erreurs de validation (ex: JSON mal formé) alors que le backend est sain, on sait que c'est le cache qui est vérolé.
Le traçage distribué est crucial ici pour remonter jusqu'à la source de la donnée corrompue.
Et pour le cache empoisonné, comment vous différenciez une corruption de données d'un simple pic de trafic ?
On évite les usines à gaz comme Istio si c'est possible. On implémente ça directement dans le code applicatif avec des librairies type
resilience4j, pilotées par les données de notreHealingPolicy.Le but est de rester simple : le contrôleur Kubernetes met à jour une configmap, l'app reload sa conf et ajuste ses seuils.
La gestion du
Circuit Breaker Adaptatif, vous le couplez avec quoi ? Istio ou un truc maison ?C'est culturel. Au début, ils voient ça comme une perte de contrôle. Faut leur montrer les logs du
Dry-Run: "Regarde, le système a détecté une fuite mémoire à 3h du mat et a drainé le trafic proprement avant que tu te réveilles."Une fois qu'ils comprennent qu'ils dorment mieux, ils deviennent les plus grands fans.
Le
Dry-Run, c'est la base, mais est-ce que vous avez des retours sur l'acceptation de ces systèmes par les équipes de dév ? Les miens flippent dès qu'on parle de supprimer des pods sans leur accord.On évite justement les sidecars lourds pour le monitoring pur. On passe par des agents qui lisent directement les buffers
perf_event_opendu noyau.C'est bien plus efficace qu'un proxy en user-space qui doit deserialiser tout le trafic.
J'ai testé un truc similaire avec des
Sidecarsmais la latence induite par le proxy était trop élevée. Vous gérez comment l'impact performance dans votre modèle ?C'est pour ça que j'ai mis en place des
cooldown. Si une action est exécutée, le système attend un temps défini avant de retenter quoi que ce soit.L'idée est de laisser le temps au système de stabiliser ses métriques. Si après X tentatives ça bouge pas, l'opérateur doit passer en mode manuel. C'est pas une IA magique, faut des garde-fous.
Le coup de la CRD
HealingPolicy, c'est sympa, mais comment tu gères la boucle de feedback si l'actionclear-cachene fait qu'empirer la situation ?T'as raison de soulever le point. L'
eBPFest puissant mais demande une rigueur chirurgicale. L'idée ici n'est pas de tout sonder sauvagement, mais de cibler des hooks spécifiques pour minimiser l'overhead.Si t'as peur du kernel panic, commence par des outils comme
bccoubpftracedans des environnements de staging avant de pousser ça sur tes nodes critiques.C'est bien beau la théorie, mais mettre en place de l'
eBPFpour monitorer les latences en prod, c'est pas le meilleur moyen de se prendre un kernel panic si on maîtrise pas bien ses sondes ?