Chaque agent de monitoring que vous déployez dans votre cluster Kubernetes est une taxe silencieuse prélevée sur votre processeur
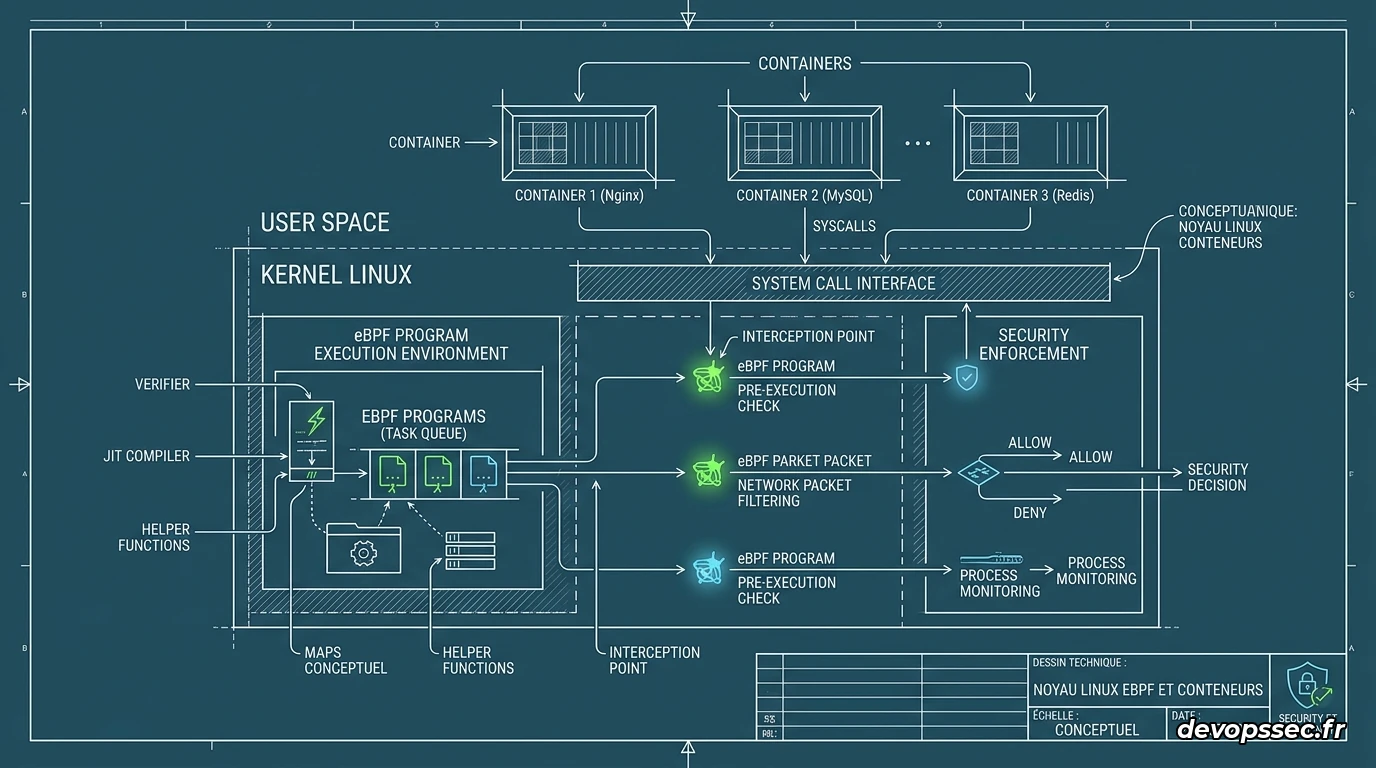
À mesure que vos microservices se multiplient, l'architecture traditionnelle par agents tiers (les fameux conteneurs sidecars) s'essouffle rapidement. Chaque conteneur supplémentaire consomme de la mémoire vive, ajoute de la latence réseau à cause des allers-retours dans la pile TCP/IP et complexifie la maintenance de vos fichiers de configuration. Pour dépasser ces limites physiques, les équipes DevOps matures se tournent désormais vers le noyau Linux.
Pourquoi le sidecar pattern s'effondre à grande échelle
Dans un modèle d'observabilité classique, chaque Pod embarque un conteneur proxy qui intercepte le trafic entrant et sortant. Pour imager cela, imaginez que pour chaque maison d'un quartier, un inspecteur doive se tenir sur le pas de la porte pour ouvrir, inspecter, puis refermer chaque colis. À l'échelle d'un cluster de production de plusieurs centaines de nœuds, cette méthode génère un goulot d'étranglement CPU critique et augmente la latence globale.
La technologie eBPF (Extended Berkeley Packet Filter) élimine ce problème en déportant la logique d'inspection directement au sein du système d'exploitation de vos machines hôtes. Au lieu d'avoir un inspecteur devant chaque porte, nous installons un système de capteurs invisibles directement dans les fondations de la route. Vos paquets réseau circulent à vitesse maximale sans jamais avoir à subir les ralentissements liés aux changements de contexte entre l'espace utilisateur et l'espace noyau.
Préparer l'environnement de travail
Pour exploiter la puissance d'eBPF dans Kubernetes, nous allons utiliser Cilium, le moteur réseau de référence pour la production. Avant de démarrer, assurez-vous de disposer d'un cluster Kubernetes doté d'un noyau système récent. Les fonctionnalités avancées de routage eBPF requièrent au minimum la version 5.4 du système Linux, mais nous recommandons vivement une version égale ou supérieure à 5.15 pour bénéficier des optimisations réseau les plus stables.
Vérifiez d'abord la version du noyau de vos nœuds de calcul avec la commande suivante :
uname -rRésultat:
5.15.0-105-genericSi vos nœuds valident ce prérequis, nous pouvons installer l'outil d'amorçage de notre nouvelle infrastructure réseau. Nous utiliserons le gestionnaire de paquets Helm pour orchestrer l'installation.
Déploiement initial de Cilium pour valider l'infrastructure eBPF
Pour valider que notre cluster peut exécuter du code eBPF sans perturber les applications existantes, nous allons configurer Cilium pour qu'il remplace entièrement le composant réseau historique de Kubernetes, le célèbre mais vieillissant kube-proxy.
Remplacer le routage IPVS/iptables obsolète
Par défaut, Kubernetes utilise des règles de filtrage réseau basées sur les iptables du système d'exploitation pour rediriger le trafic vers les bons conteneurs. Lorsque votre cluster grossit et comporte des milliers de services, la mise à jour de ces règles séquentielles devient extrêmement lourde pour le processeur. Nous allons désactiver ce comportement pour confier l'intégralité du routage à eBPF.
Exécutez la commande d'installation initiale suivante en veillant à cibler le bon contexte Kubernetes :
helm repo add cilium https://helm.cilium.io/
helm repo update
helm install cilium cilium/cilium --version 1.15.5 \
--namespace kube-system \
--set kubeProxyReplacement=true \
--set k8sServiceHost=10.0.0.10 \
--set k8sServicePort=6443Analysons les paramètres essentiels de cette commande :
- kubeProxyReplacement=true : ce paramètre indique à Cilium de prendre en charge la gestion des services Kubernetes à l'aide de tables de hachage eBPF ultra-rapides, contournant ainsi totalement l'ancien mécanisme iptables.
- k8sServiceHost et k8sServicePort : ces variables définissent l'adresse IP et le port de votre serveur d'API Kubernetes. Ils permettent aux agents eBPF de s'enregistrer directement auprès du plan de contrôle sans dépendre d'un réseau déjà établi.
Vérification de l'état du moteur de filtre
Une fois le déploiement terminé, nous devons vérifier que le moteur eBPF est correctement chargé dans l'espace d'exécution de nos serveurs. Nous utilisons pour cela l'outil en ligne de commande dédié de Cilium.
kubectl -n kube-system exec daemonset/cilium -- cilium status --compactRésultat:
KVStore: Ok
Kubernetes: Ok ["1.28"]
Cilium: Ok ["1.15.5"]
NodeMonitor: Listening for events
Host routing: BPF
KubeProxyReplacement: TrueLe statut Host routing: BPF confirme que le trafic de vos conteneurs est désormais géré par des programmes compilés à la volée et injectés directement dans le système d'exploitation de vos serveurs de production. Vous venez de libérer votre cluster des limites imposées par les couches de virtualisation réseau classiques.
Architecture eBPF hautement disponible et sécurisée pour la production
Un déploiement par défaut ne suffit pas pour encaisser des pics de charge réels ou pour répondre aux exigences de conformité des entreprises. Nous allons maintenant concevoir une configuration taillée pour la haute disponibilité, en activant le contrôle de congestion réseau moderne et en mettant en place une politique de sécurité granulaire basée sur les identités des charges de travail.
Configuration avancée du moteur pour la haute disponibilité
Nous allons créer un fichier de configuration nommé values-prod.yaml pour structurer notre environnement de production. Ce fichier active le protocole de contrôle de congestion réseau BBR et configure la collecte de métriques système nécessaires au monitoring.
# values-prod.yaml
kubeProxyReplacement: "true"
bbr:
enabled: true
bandwidthManager:
enabled: true
hubble:
enabled: true
metrics:
enabled:
- dns
- drop
- httpV2:port=80,8080
- icmp
- flow
serviceMonitor:
enabled: true
relay:
enabled: true
ui:
enabled: true
resources:
limits:
cpu: 1000m
memory: 1024Mi
requests:
cpu: 200m
memory: 512Mi
ipam:
mode: "kubernetes"Étudions en profondeur les mécanismes de production activés par cette configuration :
- bbr.enabled=true : active l'algorithme de contrôle de congestion BBR développé par Google. Cet algorithme calcule en permanence le chemin le plus rapide pour acheminer vos données sans saturer la bande passante disponible, réduisant drastiquement la latence réseau lors des fortes charges.
- bandwidthManager.enabled=true : délègue la gestion de la bande passante au sous-système de contrôle du trafic du noyau Linux, empêchant un conteneur défaillant d'accaparer l'intégralité de la bande passante physique d'un serveur.
- hubble.enabled=true : déploie le moteur d'observabilité Hubble, qui extrait passivement les métriques de sécurité et de réseau directement depuis les appels eBPF, sans consommer de CPU supplémentaire pour vos conteneurs applicatifs.
Pour appliquer cette configuration robuste sur votre cluster, mettez à jour votre déploiement existant à l'aide de la commande suivante :
helm upgrade cilium cilium/cilium \
--namespace kube-system \
--values values-prod.yamlIsolation des ressources
Pensez toujours à définir des limites de ressources (limits et requests) pour les agents réseau sur vos clusters de production. Si un pic d'appels réseau survient, ces agents doivent disposer d'assez de puissance de calcul pour traiter les paquets sans risquer d'être arrêtés par le gestionnaire de mémoire de Kubernetes.
Sécurisation de la couche applicative avec CiliumNetworkPolicy
La sécurité réseau par adresses IP est inefficace dans Kubernetes en raison du cycle de vie éphémère des conteneurs. Grâce à eBPF, nous pouvons analyser le trafic jusqu'à la couche applicative (couche 7) en utilisant les identités cryptographiques des pods. Nous allons définir une règle de sécurité stricte interdisant tout trafic vers notre API de production, sauf celui provenant explicitement de notre service frontal.
Créez le fichier de configuration de sécurité production-security-policy.yaml suivant :
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: api-gateway-security
namespace: production
spec:
endpointSelector:
matchLabels:
app: api-gateway
ingress:
- fromEndpoints:
- matchLabels:
app: frontend
toPorts:
- ports:
- port: "8080"
protocol: TCP
rules:
http:
- method: "GET"
path: "/api/v1/public"Voici une explication des éléments clés de cette structure de sécurité :
- endpointSelector : cible précisément les pods applicatifs portant le label app: api-gateway auxquels la règle de sécurité va s'appliquer.
- fromEndpoints : n'autorise la connexion réseau que si le conteneur émetteur possède l'identité certifiée app: frontend, rendant caduque toute tentative d'usurpation d'adresse IP interne.
- rules.http : applique une restriction de niveau applicatif (Couche 7). Même si un pirate parvient à communiquer avec le port 8080, seuls les appels de type HTTP GET vers l'adresse précise /api/v1/public seront autorisés par le noyau de la machine.
Appliquez cette règle de sécurité au sein de votre environnement de production :
kubectl apply -f production-security-policy.yamlSi une tentative d'appel non autorisée (par exemple une tentative de suppression de données via une requête POST ou un accès à un chemin sensible) survient, le noyau Linux intercepte et rejette immédiatement le paquet réseau. Vous pouvez observer ce comportement en temps réel dans les journaux système de Hubble :
kubectl exec -n kube-system -c cilium-agent daemonset/cilium -- hubble observe --type dropRésultat:
Jan 15 14:32:01.405: src=production/frontend-74d75-abcde dst=production/api-gateway-8f8d-12345 dport=8080 policy-denied L7 http-request DROPPED (HTTP/1.1 POST /api/v1/delete)Conclusion : Le noyau Linux comme nouveau plan de contrôle
En remplaçant les mécanismes réseau traditionnels par un système de filtrage et de routage géré directement au niveau du système d'exploitation, vous venez de faire franchir un cap décisif à vos infrastructures de production. Votre cluster est maintenant capable de traiter des flux de données massifs tout en consommant une fraction négligeable des ressources de calcul de vos serveurs.
Les bénéfices concrets à long terme
L'adoption d'un réseau basé sur eBPF ne se limite pas à un simple gain de performances. Elle offre à vos équipes d'ingénierie DevOps une visibilité totale et instantanée sur l'état de santé du système, tout en simplifiant drastiquement les règles de sécurité. Plus besoin d'injecter des proxies complexes ou de maintenir des configurations réseau spécifiques par application : le noyau de vos serveurs s'occupe de tout de manière uniforme et hautement sécurisée.
Alors que la complexité des environnements cloud continue de croître, maîtriser le fonctionnement interne du système d'exploitation et savoir interagir avec lui via des technologies comme eBPF s'impose comme une compétence indispensable pour concevoir les architectures de production de demain.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
29 commentaires
Merci pour le tuto, c'est limpide. Je passe en test sur le cluster staging demain.
BBR change la donne sur les liens saturés. Il détecte la congestion avant que tes buffers ne débordent. Active-le, tu verras une baisse immédiate des drops.
Le
bbrest vraiment efficace ? J'ai des soucis de saturation sur mes liens inter-nœuds.Vérifie bien que le label sur le pod est identique à celui du
endpointSelector. Une faute de frappe dansmatchLabelsest vite arrivée.J'ai des logs
policy-denieddans Hubble alors que j'ai bien mis mes labels. Je comprends pas pourquoi.Non, eBPF gère le routage et la sécu bas niveau. Pour du routage L7 complexe ou du TLS termination, garde ton Ingress, mais il sera beaucoup plus rapide car il s'appuiera sur Cilium.
Est-ce que eBPF peut remplacer totalement un Ingress Controller comme Nginx ?
Oui, fais un
kubectl rollout restart ds/cilium -n kube-systempour forcer la prise en compte des nouvelles limites CPU/RAM.Mon
values-prod.yamlest bien pris en compte, mais mes ressources ne sont pas limitées comme prévu. Je dois redémarrer les pods ?tcpdumpest intrusif et capte tout le bruit.hubbleutilise les événements eBPF pour te donner une vue structurée, centrée sur tes Pods et tes services. C'est le jour et la nuit.C'est quoi la différence concrète entre
hubble observeet untcpdumpclassique ?Ravi d'entendre ça. C'est tout l'intérêt d'eBPF : moins de couches, moins de latence. Bonne prod.
Merci, le passage en 5.15 a tout réglé pour moi. C'est impressionnant la différence sur la latence réseau.
Tu as probablement un ancien résidu de
kube-proxyou une autre instance de Cilium qui traîne. Nettoie les fichiers dans/sys/fs/bpfsur le nœud concerné.J'ai une erreur
BPF: File existsquand je lance le daemonset. Une idée ?C'est possible mais sensible. Fais un
helm upgradeprogressif. Le changement se fait en temps réel, mais vérifie bien que tes règles iptables ne sont pas en conflit avant.Pour le
kubeProxyReplacement, on peut le faire sur un cluster déjà en prod ou ça va couper tout le trafic réseau pendant l'update ?C'est l'inverse. Ça délègue au noyau, donc ça réduit la charge CPU par rapport à une gestion logicielle classique. Juste, respecte bien les
limitsdans ton fichier de config.Le
bandwidthManagerconsomme beaucoup sur le CPU ? J'ai peur pour mes petits nœuds.Il te manque la partie
toPortspour définir le protocole et le chemin HTTP. Sans ça, le filtre L7 est incomplet. Complète avec ça :J'ai testé le
CiliumNetworkPolicymais mes flux L7 passent pas. Voici mon YAML :C'est censé suffire ?
Vérifie tes ports. Il faut que
hubblesoit activé dans tonvalues-prod.yamlet que le service soit exposé. T'as bien configuré le relay ?Je bloque sur
hubble observe. Ça me renvoieconnection refusedalors que le pod est bien en Running.Non, Cilium est nativement compatible avec les
NetworkPolicystandards. Il va juste remplacer la manière dont les règles sont appliquées par le noyau. C'est plus propre, plus rapide.Est-ce que
kubeProxyReplacementva foutre le bazar avec mesNetworkPolicyactuelles ?