Les coulisses du drame silencieux de la production Kubernetes
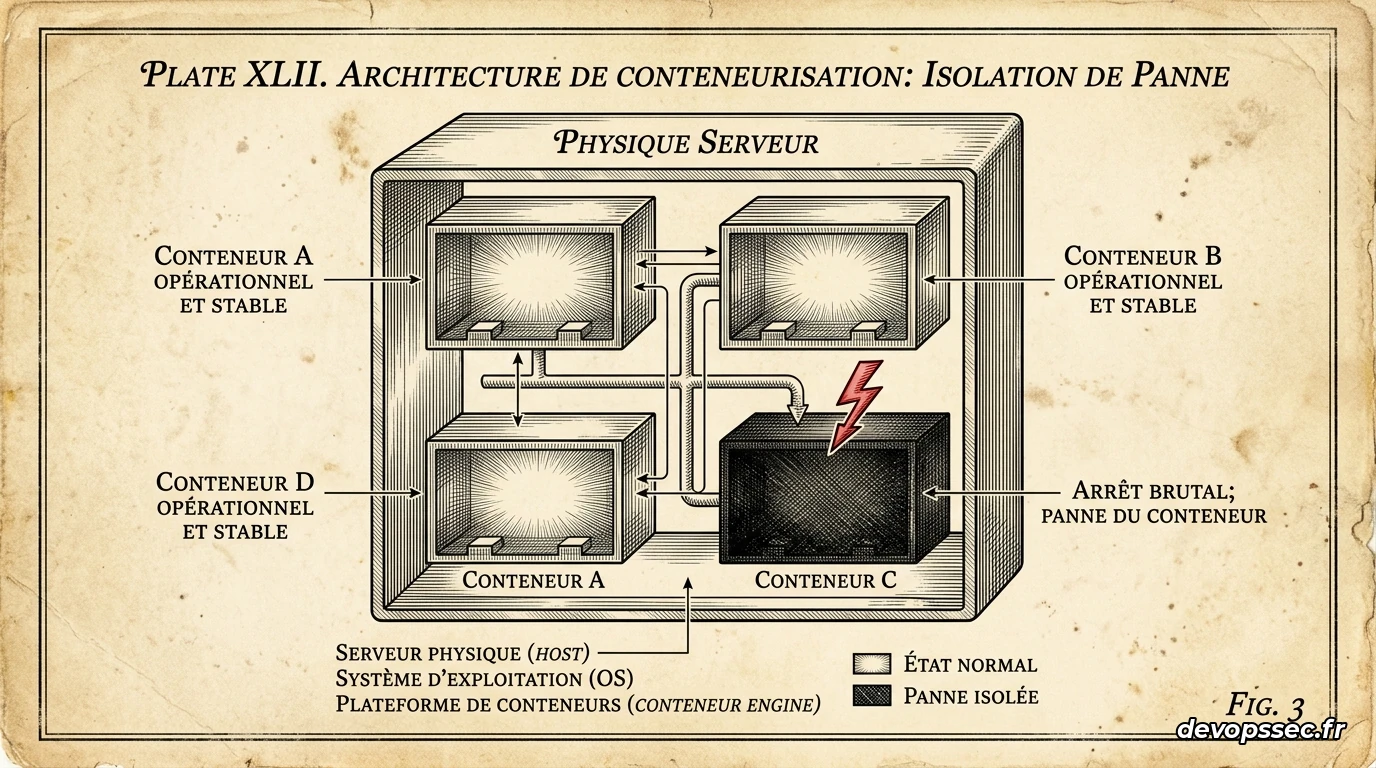
Un appel d'astreinte au milieu de la nuit révèle qu'un pod applicatif s'est arrêté brutalement sans laisser de traces dans les logs applicatifs traditionnels. Ce phénomène frustrant est souvent le résultat d'un arbitrage forcé du système d'exploitation, un mécanisme de protection ultime qui ne laisse aucune chance à votre code pour s'arrêter proprement.
Comprendre l'anatomie du signal SIGKILL
Le coupable de cette disparition brutale s'appelle le Out Of Memory (OOM) Killer, un composant natif du noyau Linux conçu pour préserver la stabilité du système hôte. Imaginez un videur dans une boîte de nuit bondée qui doit expulser un client trop bruyant pour éviter que la structure entière ne s'effondre sous la pression.
Dans un environnement conteneurisé, le noyau s'appuie sur les cgroups pour surveiller et limiter la consommation de ressources de chaque conteneur. Lorsque la mémoire d'un conteneur dépasse la limite qui lui a été fixée par les configurations du pod, le noyau Linux lui envoie immédiatement un signal non interceptable pour forcer son arrêt immédiat.
Le piège des logs applicatifs vides
La réception d'un signal d'arrêt forcé ne laisse pas le temps à des frameworks comme Spring, NestJS ou.NET d'exécuter leurs routines de fermeture propre, ce qui explique l'absence totale de traces applicatives dans vos agrégateurs de logs.
Configurer son environnement pour traquer et reproduire l'OOMKilled
Pour résoudre méthodiquement les incidents de saturation de mémoire, nous devons installer les outils d'observation adéquats et configurer notre terminal pour interroger directement l'API de Kubernetes. Cette phase préparatoire nous permettra de simuler un dépassement de charge en toute sécurité sans impacter nos environnements sensibles.
Les outils indispensables du débogage mémoire
La première étape consiste à déployer le serveur de métriques officiel au sein de votre cluster de test afin d'exposer les données de consommation en temps réel. Sans ce composant, les commandes d'inspection rapide de ressources renverront des erreurs de communication.
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yamlCette commande déploie l'agent de collecte qui interroge les démons Kubelet de chaque nœud pour consolider les statistiques d'utilisation de la mémoire vive et du processeur.
Détecter les pods en détresse via CLI
Une fois les métriques actives, vous devez maîtriser la syntaxe d'extraction spécifique permettant d'isoler les conteneurs ayant subi un arrêt forcé. Nous allons utiliser des filtres d'affichage évolués pour cibler l'indicateur d'état d'erreur caractéristique de l'éviction mémoire.
kubectl get pods -n default -o jsonpath='{range .items[*]}{.metadata.name}{"\t"}{.status.containerStatuses[*].lastState.terminated.reason}{"\n"}{end}'Résultat:
payment-service-api-7f84 OOMKilled
auth-service-5b9c Completed
notification-worker-3d21 OOMKilledLa commande utilise un sélecteur complexe pour parcourir l'historique d'extinction de tous les conteneurs d'un espace de noms, mettant en lumière le motif explicite de l'arrêt du processus.
L'implémentation initiale : Déclencher et observer un dépassement de mémoire
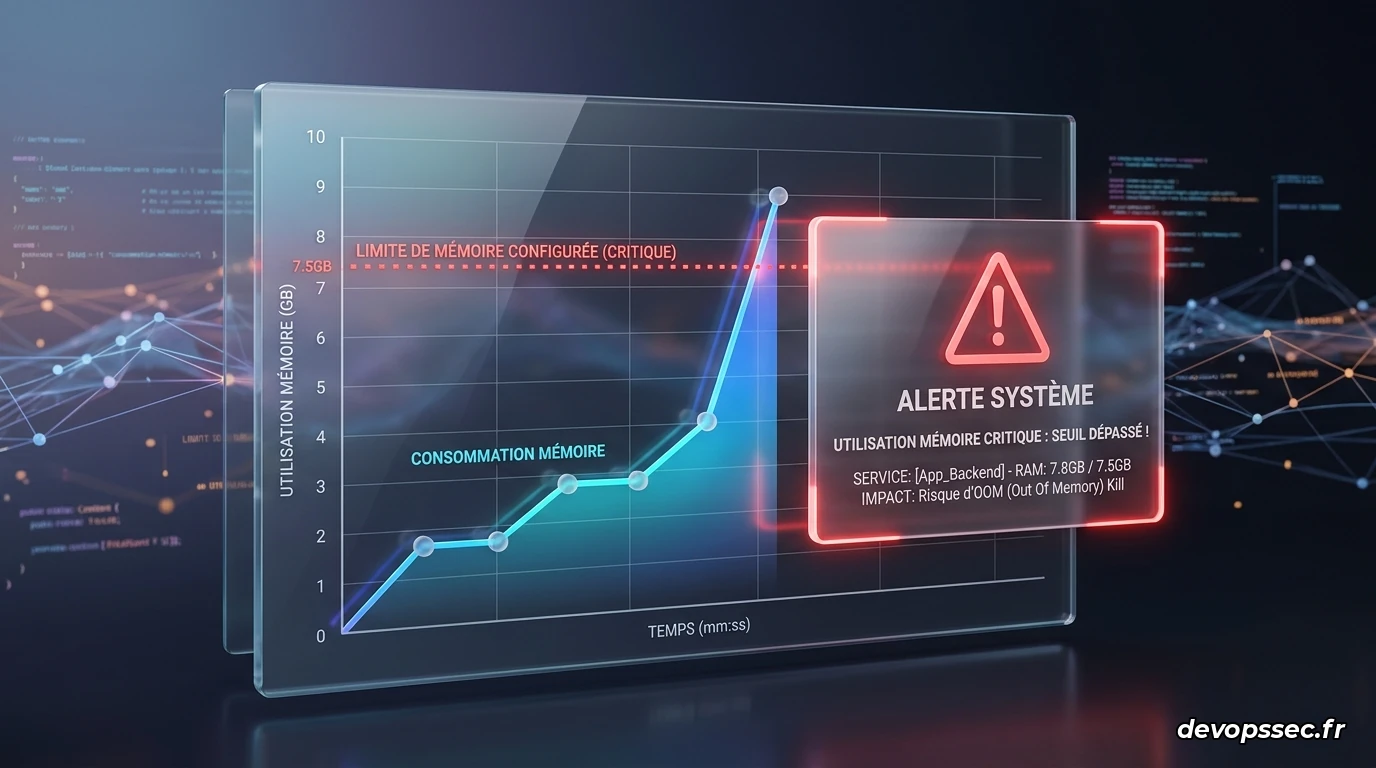
Afin de valider notre chaîne de détection, nous allons déployer un conteneur configuré volontairement avec des ressources insuffisantes. Nous allons injecter une charge synthétique pour forcer le système d'exploitation à éliminer notre processus cobaye.
Un déploiement témoin pour valider le comportement
Nous définissons un fichier de configuration nommé memory-leak-demo.yaml contenant des limites strictes et un utilitaire d'injection de contrainte mémoire.
apiVersion: apps/v1
kind: Deployment
metadata:
name: memory-stress-test
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: stress-app
template:
metadata:
labels:
app: stress-app
spec:
containers:
- name: stress-container
image: polvi/stress
resources:
limits:
memory: "64Mi"
requests:
memory: "32Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "100M", "--vm-hang", "2"]Analysons les paramètres clés de cette configuration didactique :
- limits.memory : Fixé à 64Mi, représentant le plafond de mémoire absolue alloué par le système au conteneur.
- requests.memory : Configuré à 32Mi, garantissant que le nœud d'accueil dispose au moins de cette quantité disponible lors du placement du pod.
- --vm-bytes 100M : Indique à l'outil de simulation de réclamer immédiatement 100 Mo de mémoire vive, ce qui dépasse largement la limite autorisée de 64 Mo.
Analyse du rapport d'autopsie système
Après application du manifeste, le planificateur de Kubernetes lance le conteneur qui tente d'allouer la mémoire demandée par l'utilitaire interne. Le couperet tombe instantanément sous la forme d'un redémarrage en boucle.
kubectl describe pod -l app=stress-appRésultat:
Containers:
stress-container:
Container ID: containerd://e8f23...
Image: polvi/stress
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Mon, 25 May 2026 14:02:01 +0200
Finished: Mon, 25 May 2026 14:02:02 +0200La présence du code de retour système Exit Code: 137 confirme de manière absolue que le conteneur a été éliminé par un signal externe équivalent à un arrêt brutal non négociable.
L'implémentation Production-Ready : Blindage et auto-scaling

En production, vous ne pouvez pas vous permettre de laisser vos applications s'éteindre de manière désordonnée. Nous devons implémenter une architecture robuste combinant une gestion stricte des priorités d'ordonnancement, des configurations adaptées aux runtimes modernes et des limites élastiques.
Le triptyque d'or : Requests, Limits et classes de QoS
Le planificateur de Kubernetes classe vos pods selon trois niveaux de priorité appelés Quality of Service (QoS), déterminant l'ordre de sacrifice des processus en cas de pénurie globale sur le nœud physique.
- Guaranteed : Attribué si les requêtes et les limites de mémoire et de processeur sont strictement identiques. C'est le niveau de résilience le plus élevé.
- Burstable : Attribué si les limites sont supérieures aux requêtes de ressources. Pratique pour absorber des pics temporaires mais sujet à l'éviction.
- BestEffort : Attribué si aucune ressource n'est déclarée. Ces pods sont les premiers éliminés à la moindre alerte de charge sur le nœud.
Voici l'implémentation de référence pour un microservice écrit en Go ou Java nécessitant un comportement déterministe et une sécurité mémoire de niveau bancaire.
apiVersion: apps/v1
kind: Deployment
metadata:
name: payment-api-prod
namespace: finance
labels:
app.kubernetes.io/name: payment-api
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 0
selector:
matchLabels:
app: payment-api
template:
metadata:
labels:
app: payment-api
spec:
securityContext:
runAsNonRoot: true
runAsUser: 10001
containers:
- name: payment-service
image: golang:1.22-alpine
command: ["/app/server"]
env:
- name: GOMEMLIMIT
value: "460MiB"
resources:
requests:
memory: "512Mi"
cpu: "500m"
limits:
memory: "512Mi"
cpu: "1000m"
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
readinessProbe:
httpGet:
path: /readyz
port: 8080
initialDelaySeconds: 5
periodSeconds: 10Explications détaillées de la configuration de production :
- requests.memory et limits.memory : Définis tous deux à 512Mi, forçant l'attribution de la classe de service Guaranteed et évitant que le pod ne soit chassé au profit d'autres processus gourmands.
- GOMEMLIMIT: "460MiB" : Variable d'environnement propre au runtime Go, configurée à 90% de la limite totale du conteneur. Cela force le ramasse-miettes interne à se déclencher avant que le noyau Linux ne décide d'abattre le processus.
- securityContext : Restreint les privilèges du conteneur en interdisant l'exécution en tant que superutilisateur, limitant ainsi la portée d'une éventuelle faille de sécurité.
Cartographier les flux de gestion mémoire
Pour mieux visualiser la cinétique d'une demande de ressources et le déclenchement des mécanismes de sécurité au sein de l'architecture, étudions le diagramme de flux ci-dessous.
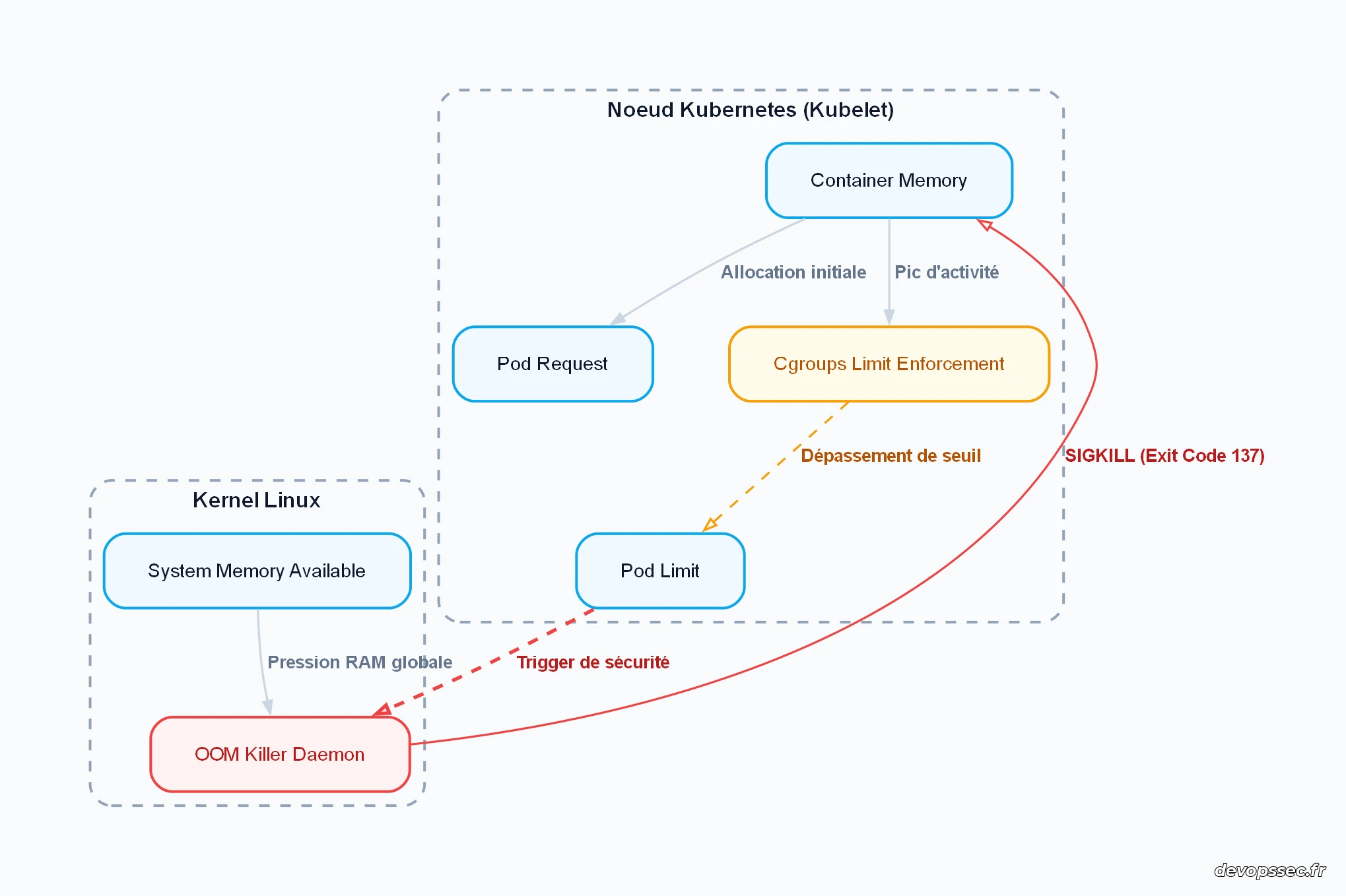
Ce schéma illustre comment la mémoire allouée à un conteneur transite par les filtres de contrôle des cgroups. Dès que la consommation dépasse la limite autorisée par le profil de configuration, le démon de surveillance du noyau s'active pour libérer l'espace en coupant instantanément le processus fautif.
Maîtriser le monitoring préventif des dérives mémoire
La meilleure façon de gérer un crash mémoire est d'anticiper sa survenue en analysant les tendances de consommation à l'aide de métriques précises récoltées en continu.
Alerting Prometheus et requêtes PromQL indispensables
Nous allons mettre en place une alerte préventive basée sur la vitesse d'accumulation de données en mémoire vive. L'objectif est d'être averti avant que le conteneur n'atteigne le point de non-retour.
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: kubernetes-oom-alerts
namespace: monitoring
spec:
groups:
- name: memory-checks
rules:
- alert: ContainerMemorySaturationWarning
expr: (sum(container_memory_working_set_bytes) by (pod, namespace) / sum(kube_pod_container_resource_limits{resource="memory"}) by (pod, namespace)) * 100 > 85
for: 5m
labels:
severity: warning
annotations:
summary: "Saturation critique de la memoire pour le pod {{ $labels.pod }}"
description: "Le conteneur utilise plus de 85% de sa limite de memoire autorisee depuis plus de 5 minutes."Cette règle d'alerte calcule le ratio entre la mémoire de travail active et la limite matérielle déclarée. Si ce ratio dépasse les 85% de manière continue pendant cinq minutes, une notification d'avertissement est immédiatement expédiée à vos équipes d'exploitation.
Pourquoi container_memory_working_set_bytes ?
Nous utilisons cette métrique spécifique plutôt que la mémoire brute car elle inclut les caches de fichiers actifs qui ne peuvent pas être facilement libérés par le système, fournissant ainsi l'indicateur le plus fidèle de la pression mémoire réelle.
Conclusion : De la réaction à l'anticipation
La résolution durable des erreurs d'allocation mémoire dans Kubernetes ne consiste pas simplement à augmenter de manière disproportionnée les limites de vos conteneurs, une approche coûteuse et inefficace. Une gestion saine repose sur l'alignement strict de vos demandes d'allocation avec les profils réels d'exécution de vos applications, tout en configurant intelligemment vos environnements d'exécution pour collaborer avec le planificateur du cluster.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
26 commentaires
Oui, tu peux tracker les
kube_pod_container_status_terminated_reasonavec une requête type :Pour monitorer les OOM, est-ce que
kube-state-metricssuffit ?Requests = ce que tu réserves (garanti). Limits = le plafond max. Si tu dépasses la limite, tu te fais éjecter. C'est simple.
C'est quoi la différence entre
requestsetlimitsen vrai ? J'ai toujours un doute.Nickel. Le runtime Go est beaucoup plus stable quand il sait exactement combien de mémoire il a à disposition. C'est la base.
J'ai implémenté le
GOMEMLIMITet mes crashs ont disparu. Merci pour l'astuce !Presque toujours. C'est 128 + 9 (SIGKILL). Si c'est pas un OOM, c'est que quelqu'un ou quelque chose a envoyé un
kill -9manuel sur le process.Le
Exit Code: 137c'est systématiquement un OOM ?Augmente temporairement la limite juste pour le debug ou utilise un
sidecarqui dump la mémoire avant que le process ne soit tué.Comment on debug une fuite mémoire quand le pod crash avant qu'on ait pu faire un
heap dump?Fais ça via Kubernetes, c'est lui qui gère le cycle de vie. Ne touche pas aux
cgroupsmanuellement sur les nodes, tu vas casser l'orchestration.Est-ce que je peux limiter la mémoire avec
cgroups v2directement sans passer par les manifs yaml ?Il te manque sûrement les permissions RBAC sur ton service account. Vérifie tes logs d'audit.
J'ai une erreur
forbiddenquand je lance le déploiement dumetrics-server. Je suis en cluster privé.Si tu as des alertes tout le temps, c'est que ton application est mal dimensionnée ou a une fuite mémoire. Regarde tes
container_memory_working_set_bytes, tu as peut-être un cache qui ne se vide jamais.Le
PrometheusRuleest top. Par contre, 85% c'est pas un peu agressif ? Je reçois des alertes toute la journée.Pour du traitement lourd, Guaranteed est obligatoire. Tu veux éviter à tout prix que le noyau ne tue ton job en plein milieu d'un rendu.
Est-ce qu'il vaut mieux utiliser
GuaranteedouBurstablepour un worker qui fait du traitement d'image lourd ?Vérifie ton namespace. Si tu n'as pas spécifié
-n, il cherche dansdefault. Sinon, check si lemetrics-serverest bien up.J'ai testé votre requête
jsonpathmais elle me renvoie rien du tout sur mon cluster EKS. Une idée ?Pour Java, joue sur
-XX:MaxRAMPercentage. Ajuste-le pour qu'il soit légèrement inférieur à ta limite Kubernetes pour laisser respirer la heap.Je bosse sur du Java, le
GOMEMLIMITne fonctionne pas pour moi évidemment. Il y a une équivalence pour la JVM ?Le risque c'est de fausser le scheduler. Si tout le monde fait ça, le node sature physiquement et tu déclenches des évictions en cascade. Ne jamais surallouer sans contrôle.
Merci pour le tuto. Question bête : si je mets
limits.memoryà une valeur très haute pour être tranquille, c'est quoi le risque réel à part le coût ?Si c'est un OOM, tu verras le code 137 dans le status. Utilise
kubectl describe podcomme indiqué dans le tuto. Si tu voisOOMKilled, c'est que le noyau a tranché.