Le mirage de la délocalisation du terminal
Frapper une touche de son clavier, attendre une demi-seconde que la lettre apparaisse à l'écran, puis voir sa connexion interrompue car le VPN d'entreprise vient de renégocier ses clés. Bienvenue dans le quotidien suffocant du développeur moderne, otage d'une industrie qui a cru bon de déporter l'intégralité de son espace de travail sur des serveurs distants. La promesse initiale était pourtant séduisante : un environnement standardisé, accessible depuis n'importe quel navigateur, épargnant aux équipes les sempiternels problèmes de configuration locale.
Cependant, après plusieurs années de déploiements massifs en entreprise, le constat sur le terrain est amer. L'engouement initial pour ces solutions centralisées s'est heurté au mur implacable de la physique des réseaux et de l'inflation des coûts d'infrastructure. Nous assistons aujourd'hui à un véritable retour de balancier, un mouvement où les ingénieurs réclament à nouveau la souveraineté de leur machine pour garantir leur productivité. Il est temps de disséquer ce grand désenchantement et de comprendre pourquoi le paradigme de l'exécution locale redevient le standard incontesté pour les équipes de haute performance.
L'onboarding en un clic : autopsie d'une promesse brisée
L'argument commercial majeur des environnements de développement cloud réside dans la suppression du fameux syndrome du ça marche sur ma machine
. En encapsulant les dépendances dans des conteneurs de développement hébergés à distance, les nouveaux arrivants sont censés être opérationnels en quelques minutes. C'est une vision idyllique qui fonctionne parfaitement pour des projets de démonstration ou des applications monolithiques simples. Dans la réalité des architectures d'entreprise complexes, cette belle mécanique s'enraye rapidement.
La standardisation au détriment de la flexibilité
L'utilisation de fichiers de configuration stricts impose un cadre rigide qui nivelle par le bas l'expérience de développement. Imaginez louer un appartement meublé luxueux : c'est très confortable au début, mais vous n'avez pas le droit de changer la disposition des meubles ni d'installer vos propres outils de cuisine. Le développeur senior, habitué à ses scripts personnalisés, ses alias et ses outils d'analyse de performance locaux, se retrouve prisonnier d'un environnement générique et verrouillé par l'équipe de sécurité de l'entreprise.
Le fichier de configuration devient alors un goulot d'étranglement complexe. Pour satisfaire les besoins de tous les profils (front-end, back-end, data), ces définitions s'alourdissent, transformant un conteneur censé être léger en une usine à gaz longue à démarrer. Voici un exemple typique de configuration alourdie pour tenter de couvrir tous les cas d'usage :
{
"name": "Backend-Microservices-Monolith",
"build": {
"dockerfile": "Dockerfile.dev",
"args": { "VARIANT": "18", "INSTALL_NODE": "true" }
},
"customizations": {
"vscode": {
"extensions": [
"golang.go",
"ms-python.python",
"hashicorp.terraform",
"eamodio.gitlens"
]
}
},
"forwardPorts": [8080, 5432, 6379, 9090],
"postCreateCommand": "bash ./scripts/setup-heavy-deps.sh"
}Dans ce scénario, la commande définie dans la variable postCreateCommand exécute souvent des téléchargements massifs de dépendances. Le gain de temps de l'onboarding est totalement annihilé par le temps de démarrage quotidien de cet environnement distant. Le développeur se retrouve à patienter devant une barre de progression chaque matin au lieu de produire de la valeur.
Quand le réseau dicte sa loi
L'aspect le plus critique, et souvent éludé par les fournisseurs, est la dépendance absolue à la connectivité. La latence réseau est l'ennemi invisible de la concentration. Une frappe clavier ou un défilement de code qui subit un retard de quelques dizaines de millisecondes suffit à briser l'état de flux cognitif de l'ingénieur. Lors d'une panne de production critique, devoir patienter pour afficher le contenu d'un fichier de log distant ajoute un stress inutile et dangereux à une situation déjà tendue.
Risque de déconnexion critique
Lors du débogage de processus interactifs lourds (comme un step-by-step sur un thread bloqué), une micro-coupure réseau fermera violemment votre session websocket, perdant ainsi l'intégralité du contexte d'exécution en cours.
J'ai personnellement assisté à des sessions de réponse à incident où l'équipe perdait le contrôle de l'outil de développement distant simplement parce que le processus consommait trop de mémoire, figeant la machine cloud et rendant l'interface web inopérante. Les logs d'erreurs générés par ces pertes de synchronisation témoignent de la fragilité de cette architecture :
tail -f /var/log/workspace/connection-proxy.logRésultat:
[WARN] 08:42:15 - WebSocket connection latency spike detected (450ms)
[ERROR] 08:42:18 - Heartbeat timeout. Reconnecting to workspace agent...
[FATAL] 08:42:30 - Broken pipe. Client disconnected. Container OOM killed.
[INFO] 08:43:00 - Provisioning new fallback workspace... (Estimated time: 4m)Ce simple log illustre parfaitement le cauchemar opérationnel : une lenteur réseau précède un crash mémoire du conteneur distant, forçant l'ingénieur à attendre le redémarrage complet d'un nouvel environnement de secours.
La facture silencieuse des serveurs de développement
Au-delà de la frustration des équipes techniques, le modèle cloud pour le développement pose un défi financier redoutable. Les directeurs techniques sous-estiment systématiquement le coût induit par l'exécution permanente de machines virtuelles pour chaque développeur. Un ordinateur portable haut de gamme représente un investissement initial fixe, tandis que l'informatique en nuage se nourrit de facturations récurrentes à l'heure, souvent pour des ressources qui tournent à vide.
L'architecture de l'échec économique
Contrairement à un serveur de production qui encaisse un trafic constant, l'utilisation des ressources d'un développeur est extrêmement saccadée. Des pics de compilation gourmands en processeur sont suivis de longues périodes de lecture de code ou de réunions où la machine distante ne fait absolument rien. Pourtant, l'entreprise paie pour la capacité maximale réservée afin de garantir que les compilations soient rapides lorsque le besoin s'en fait sentir.
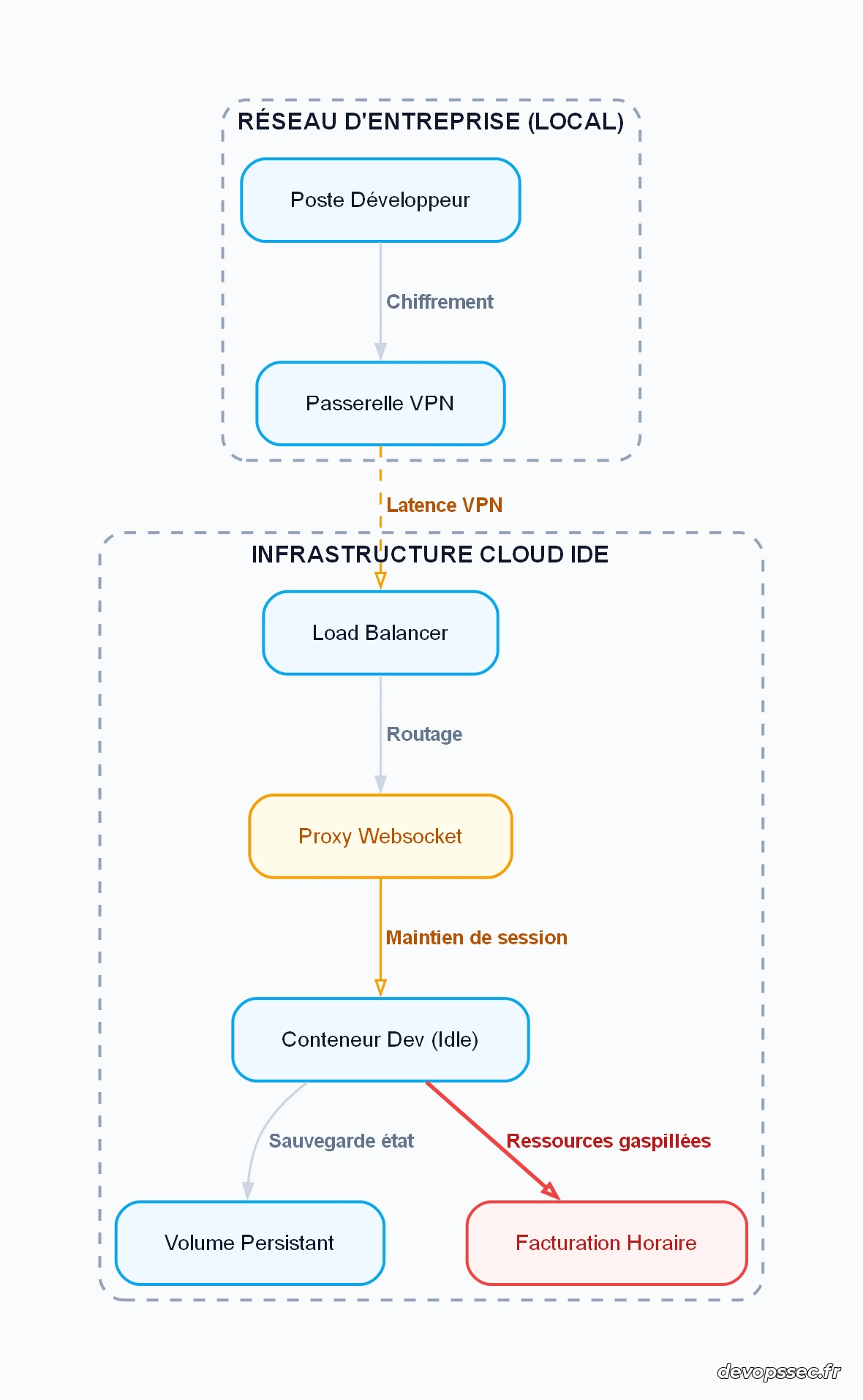
L'analyse de ce schéma révèle la complexité superflue ajoutée par ce modèle. Le flux de travail traverse une passerelle VPN introduisant une première couche de ralentissement, pour ensuite maintenir une connexion Websocket constante vers un conteneur inactif la majeure partie de la journée. Le nœud de facturation souligne l'hémorragie financière : le volume persistant et l'instance allouée consomment du budget en continu, indépendamment de l'activité réelle du développeur, transformant une commodité technique en gouffre financier.
Métriques comparatives et retour au pragmatisme
Si l'on analyse les coûts sur un cycle de vie standard de renouvellement matériel, les chiffres sont sans appel. Maintenir une instance distante disposant d'une puissance équivalente à un ordinateur portable moderne coûte exponentiellement plus cher. Les entreprises tentent de pallier cela en configurant des arrêts automatiques en cas d'inactivité, mais cela recrée immédiatement le problème du temps d'attente au redémarrage mentionné plus haut.
| Critère | Poste Local Haut de Gamme | Instance Cloud IDE (8 vCPU / 32GB) |
|---|---|---|
| Coût matériel initial | ~ 3 500 € (Amorti) | 0 € |
| Coût d'exploitation mensuel | 0 € | ~ 150 € (soit 1 800 € / an) |
| Coût total sur 3 ans | 3 500 € | ~ 5 400 € + frais réseau |
| Disponibilité hors-ligne | Totale (Train, Avion) | Nulle |
| Performances d'I/O (Disque) | SSD NVMe dédiés purs (> 5GB/s) | Volumes réseaux partagés bridés |
Ce tableau comparatif met en évidence une aberration mathématique. En s'entêtant à déporter l'exécution, les entreprises louent à prix d'or de la puissance de calcul sur-évaluée, tout en fournissant tout de même des ordinateurs portables à leurs employés pour se connecter à ces environnements distants. C'est une double dépense qui ne se justifie que rarement par des impératifs de sécurité extrêmes.
L'hybridation "Local-First" : la véritable agilité
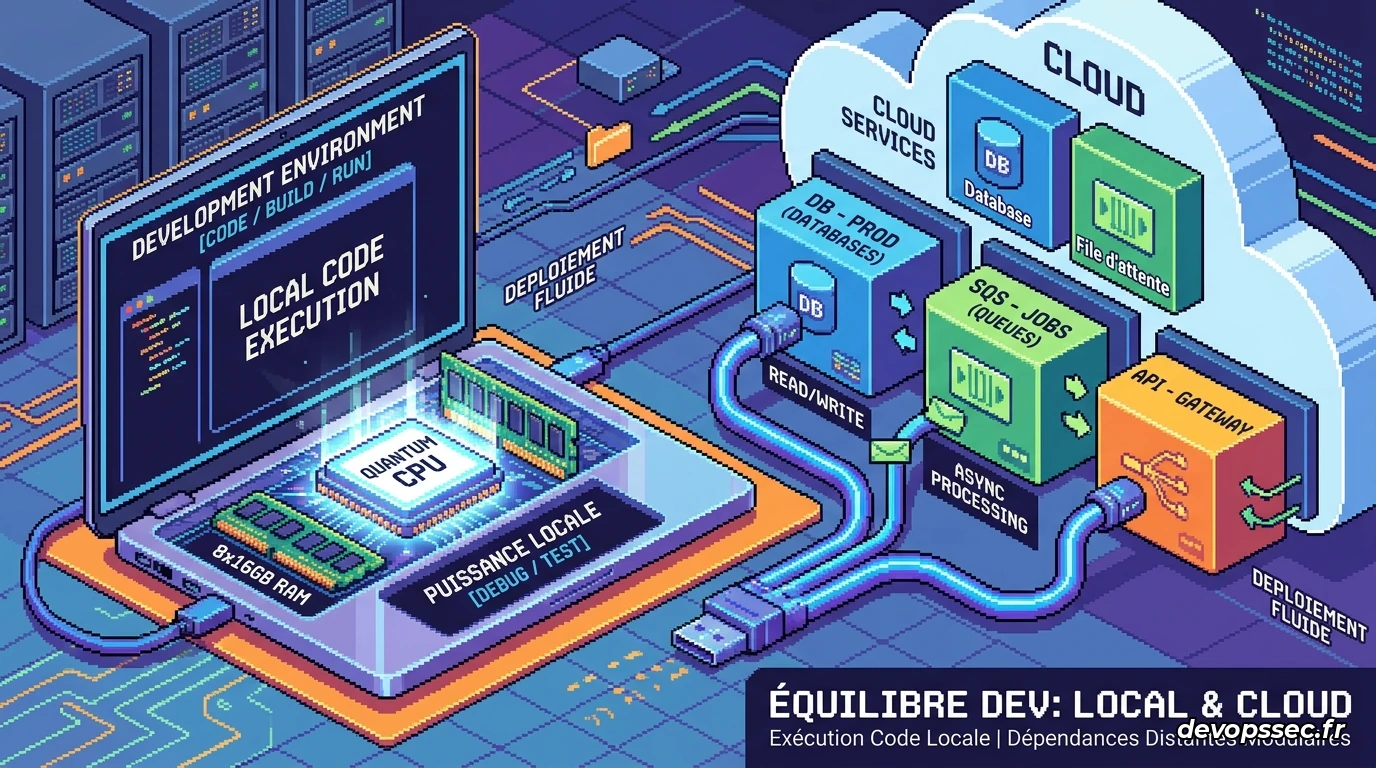
Face à ces déconvenues, l'industrie converge vers un nouveau paradigme pragmatique : l'approche Local-First hybride. L'idée fondatrice est d'exploiter l'immense puissance brute des processeurs ARM modernes et des puces de nouvelle génération présents dans nos ordinateurs, tout en déléguant intelligemment certaines charges de travail complexes à des infrastructures distantes.
L'orchestration des dépendances sur la machine locale
Plutôt que d'enfermer le code et l'éditeur dans le navigateur, les développeurs rapatrient leurs outils sur leur poste. Ils utilisent des environnements isolés locaux via des moteurs de conteneurisation allégés. L'éditeur de code tourne nativement, profitant de la vélocité du système de fichiers local et de l'accélération matérielle de l'écran, ce qui supprime totalement la latence visuelle. La configuration standardisée reste présente, mais elle décrit l'architecture locale plutôt que l'infrastructure distante.
Pour gérer les architectures en microservices sans saturer la machine physique, les équipes déploient des environnements factices allégés. Voici une approche robuste pour monter une base de données et un cache localement sans frictions, garantissant une reproductibilité parfaite :
version: '3.8'
services:
app-database:
image: postgres:15-alpine
environment:
POSTGRES_USER: dev_user
POSTGRES_PASSWORD: dev_password
POSTGRES_DB: local_service_db
ports:
- "5432:5432"
volumes:
- pgdata:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U dev_user"]
interval: 5s
timeout: 5s
retries: 5
message-broker:
image: rabbitmq:3-management-alpine
ports:
- "5672:5672"
- "15672:15672"
volumes:
pgdata:
driver: localCette configuration illustre la simplicité de l'exécution locale. En utilisant des images minimalistes estampillées alpine, le moteur Docker local provisionne les dépendances en quelques secondes. Le développeur travaille sur son code source en direct, et les services annexes s'exécutent de manière prévisible, sans nécessiter la moindre requête réseau sortante vers un hébergeur tiers.
Déléguer intelligemment grâce à l'orchestration hybride
L'hybridation prend tout son sens lorsque la machine locale atteint ses limites. Il ne s'agit plus de tout déporter aveuglément, mais de pratiquer une orchestration hybride chirurgicale. Si l'application nécessite de s'interfacer avec une immense base de données anonymisée de plusieurs téraoctets, impossible à stocker sur un disque dur portable, c'est uniquement ce composant précis qui sera hébergé dans le cloud et interrogé via un tunnel sécurisé.
Tunneling Sécurisé
Utilisez des solutions de mesh VPN ou des proxys inverses chiffrés pour relier votre environnement de développement local à des bases de données partagées ou des clusters de staging, évitant ainsi l'exposition publique de vos services en cours de développement.
De même, pour la compilation de binaires extrêmement lourds ou l'entraînement de modèles d'apprentissage automatique, les outils de développement locaux savent désormais déléguer l'exécution d'une commande spécifique à un cluster distant. Une fois la tâche lourde terminée, le résultat (le binaire ou le modèle) est rapatrié en arrière-plan. Le développeur conserve la fluidité de son interface locale, tout en bénéficiant de la puissance du cloud à la demande, uniquement quand cela est strictement nécessaire et justifié.
Reprendre le contrôle de son terminal
La technologie procède souvent par cycles d'extrêmes avant de trouver son point d'équilibre. La volonté frénétique de transformer chaque éditeur de code en une application web dépendante d'un serveur distant était une réponse dogmatique à des problèmes d'outillage local qui sont aujourd'hui largement résolus par la conteneurisation moderne. Les pannes de réseau, les temps de réponse exécrables et les factures d'hébergement exorbitantes ont fini par dissiper le brouillard marketing entourant les solutions 100% cloud.
En tant qu'ingénieurs de production, notre devoir est de concevoir des flux de travail fiables, résilients et économiques. Le retour au poste de travail souverain n'est pas une régression technologique, c'est l'affirmation d'un pragmatisme sain. En combinant la puissance de calcul locale inouïe des machines actuelles avec une utilisation tactique et parcimonieuse des services cloud pour les charges massives, nous offrons aux équipes l'environnement ultime : celui qui se fait oublier pour laisser place à la véritable ingénierie.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
17 commentaires
C'est exactement mon point. La fluidité d'un terminal local est le fondement même de l'ingénierie logicielle. Dès qu'on ajoute une couche réseau au milieu, on perd cette connexion directe avec le système.
La latence, c'est le vrai tueur de productivité. Une fois que tu as goûté à l'exécution locale, c'est impossible de revenir en arrière.
Bien vu pour le
start_period. C'est ce genre de détails qui rend l'expérience locale fluide et évite les faux positifs au démarrage.D'accord avec l'article, mais attention au
healthcheckdans ton YAML. Si le conteneur est lent à démarrer, ton service va redémarrer en boucle.Voici comment je gère ça plus proprement :
Le tableau comparatif est violent. Les chiffres ne mentent pas. 5400 euros sur 3 ans contre 3500 pour une machine locale, c'est l'aberration totale.
Le changement fait peur, surtout quand les décisions sont prises par des gens qui ne codent jamais. C'est pour ça que j'ai écrit cet article, pour donner des arguments techniques aux devs face à leurs managers.
Tout le monde se plaint mais personne ne change. On attend quoi pour débrancher ces instances coûteuses ?
Qui paie la facture AWS à la fin du mois ? Parce que faire tourner des IDE distants 24/7 pour 100 devs, ça chiffre vite en coûts cachés.
Exactement. On utilise des outils comme
devcontainerspour standardiser sans pour autant centraliser l'exécution. C'est le meilleur des deux mondes.Je ne peux pas m'empêcher de penser que c'est une question de culture d'entreprise. Si tu ne fais pas confiance à tes devs pour configurer leur environnement, tu as un problème de management, pas d'infra.
On a essayé le Cloud IDE pendant 6 mois. Résultat : 20% de productivité en moins à cause des déconnexions. On est revenus sur du local avec des scripts
Makefilebien ficelés.Le
Broken pipecité dans l'article, c'est devenu notre cauchemar quotidien.C'est là que l'approche hybride intervient. Tu ne fais pas tout tourner en local, mais tu ne déportes pas tout non plus.
Tu gardes le service sur lequel tu travailles en local, et tu pointes vers des instances de staging via un tunnel. C'est du pragmatisme, pas du dogme.
Le souci, c'est quand tu as 50 microservices. Tu ne peux pas tout faire tourner en local, ça va manger tes 64 Go de RAM en un rien de temps.
On fait comment pour les dépendances lourdes sans Cloud IDE ?
Franchement, le
docker-compose.yamlque tu montres en exemple est tellement plus simple à gérer. Pourquoi vouloir tout déporter ?Si ton service a besoin de
rabbitmqoupostgres, ça tourne nativement en 2 secondes sur ma machine.La sécurité est l'argument massue, je le concède. Mais on crée une dette technique opérationnelle immense. Le
postCreateCommandque je cite dans l'article est souvent le symptôme d'une équipe qui essaie de recréer une infra locale dans un conteneur distant.On finit par payer un surcoût monstrueux pour un résultat moins performant qu'un simple conteneur local.
Je suis d'accord, mais vous oubliez la sécurité. Dans ma boîte, interdiction formelle de cloner des dépôts sur les machines. Le
/var/log/workspace/connection-proxy.logdont tu parles, je le vois tous les jours, c'est l'enfer.Le vrai problème c'est la latence réseau. Travailler avec 100ms de ping c'est juste insupportable pour un dev.
Enfin un article qui ose dire la vérité. Le Cloud IDE c'est le syndrome de la solution en quête d'un problème. On a sacrifié le confort de frappe pour un gain de temps de config qui n'existe même pas réellement.
Ma machine locale avec ses 32 Go de RAM écrase n'importe quel conteneur distant bridé par le réseau.