Le Piège de la Vélocité Absolue et le Réveil Douloureux

Tu viens tout juste de fusionner une trentaine de modifications générées par tes agents autonomes avant même d'avoir terminé ton premier café de la journée. Sur le papier, tu te sens invincible, persuadé d'avoir atteint une productivité vertigineuse en déléguant l'écriture fastidieuse de l'infrastructure et des correctifs. Pourtant, à trois heures du matin, ton téléphone sonne avec l'insistance que seuls les incidents critiques de production possèdent : le système vient de s'effondrer et absolument personne dans ton équipe ne comprend le comportement du code qui a été déployé la veille.
Nous traversons une crise d'ingénierie majeure où l'illusion de la vitesse aveugle notre jugement technique sur le long terme. Les assistants virtuels écrivent du code à un rythme inhumain, mais ils créent également une dette technique d'une opacité sans précédent, car ce code manque cruellement d'intention architecturale. En tant que professionnels du déploiement et de la fiabilité, notre mission n'est plus seulement de livrer rapidement, mais de garantir que ce qui est expédié aujourd'hui pourra encore être audité, compris et réparé par un cerveau humain demain.
La Boîte Noire : Quand la Résolution Remplace la Compréhension
Le Mythe du Code Auto-Documenté
Le danger principal de la génération massive réside dans la complaisance qu'elle installe chez les profils les moins expérimentés de nos équipes. Lorsqu'un algorithme propose un bloc de configuration complexe qui semble résoudre un problème immédiat, la tentation de l'accepter sans le disséquer est immense. C'est exactement comme construire un gratte-ciel en confiant les plans de la plomberie à une imprimante 3D autonome : le bâtiment sera habitable le premier mois, mais à la première fuite d'eau au quinzième étage, l'équipe d'intervention devra casser tous les murs à l'aveugle pour comprendre par où passent les tuyaux.
Cette approche aveugle détruit progressivement la maintenabilité de nos applications, transformant des dépôts Git jadis limpides en véritables labyrinthes logiques. Le code produit par les modèles génératifs a souvent tendance à privilégier l'exhaustivité verbeuse au lieu de la concision astucieuse d'un ingénieur chevronné. Résultat, nous nous retrouvons avec des manifestes de déploiement gigantesques contenant des redondances inutiles et des variables codées en dur, rendant toute refactorisation future extrêmement périlleuse.
# Exemple d'un déploiement Kubernetes généré automatiquement (Mauvaise pratique)
apiVersion: apps/v1
kind: Deployment
metadata:
name: api-backend
spec:
replicas: 5
template:
spec:
containers:
- name: app
image: backend:latest
env:
- name: DB_HOST
value: "10.43.2.14" # IP codée en dur par l'agent
- name: DB_PASSWORD
value: "super_secret_ai_generated" # Faille de sécurité majeureL'Escalade Silencieuse de l'Infrastructure
L'un des scénarios les plus terrifiants que j'observe sur le terrain concerne la gestion de la capacité et la résolution des fuites de mémoire. Lorsqu'une application s'écrase parce qu'elle consomme trop de ressources, la réaction d'un agent automatisé mal configuré est presque toujours de masquer le symptôme plutôt que de soigner la maladie. Au lieu d'analyser le code pour trouver la boucle infinie ou la requête mal optimisée, le système proposera simplement d'augmenter les limites de mémoire allouées au conteneur.
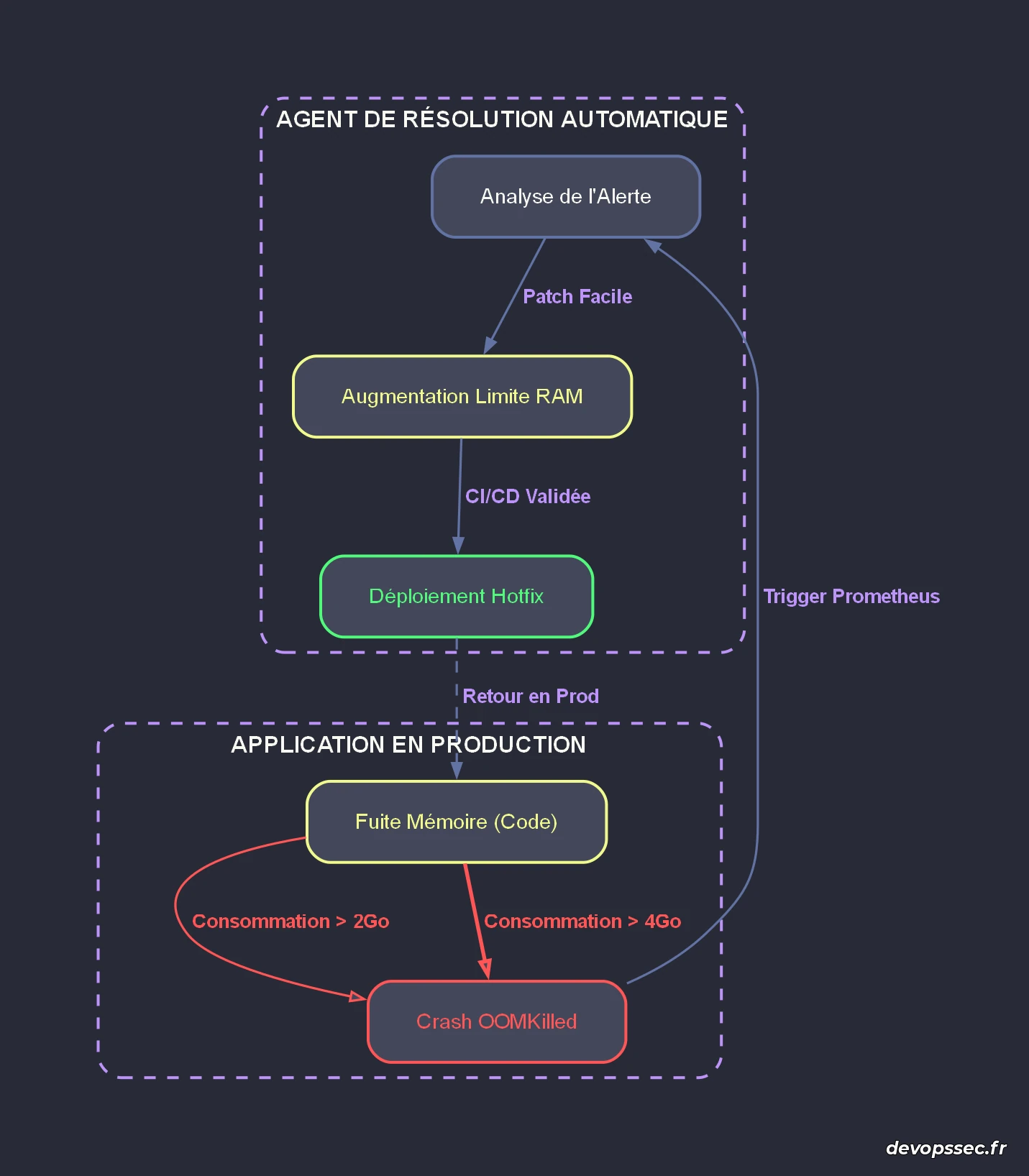
L'analyse de ce diagramme révèle le danger mortel d'une boucle de rétroaction non supervisée : l'application subit un crash critique, l'agent capte l'alerte et applique un correctif de pansement en doublant la mémoire allouée. Le cycle recommence alors inexorablement, retardant l'échéance fatale tout en multipliant les coûts d'infrastructure par dix. L'agent ne comprend pas la sémantique de la fuite mémoire, il applique une logique conditionnelle basique qui ignore totalement l'impact financier et la viabilité de l'architecture sous-jacente.
level: "error"
ts: "2026-05-25T03:14:00Z"
caller: "node_exporter"
msg: "System Out Of Memory"Résultat critique de la boucle infinie :
FATAL: Node a worker-03 has been tainted as MemoryPressure. Evicting 45 pods.
Cloud Cost Alert: Monthly estimation spiked by +400% in the last 6 hours.Redéfinir le Rôle de l'Ingénieur : De Bâtisseur à Auditeur
L'Ingénierie Inverse au Quotidien

Face à ce déluge de code auto-généré, notre métier subit une mutation profonde où la compétence reine n'est plus la vitesse de frappe, mais la capacité d'ingénierie inverse. Nous devons traiter chaque suggestion algorithmique non pas comme une vérité absolue, mais comme une hypothèse de travail potentiellement défectueuse qu'il faut valider scientifiquement. L'expert technique de demain est celui qui sait disséquer le fonctionnement d'une boîte noire, identifier ses failles logiques et exiger une simplification drastique des approches proposées par la machine.
Cette nouvelle posture exige de renforcer considérablement notre observabilité. Si nous ne maîtrisons plus chaque ligne écrite, nous devons en revanche maîtriser parfaitement le comportement du système en exécution. Il est vital de mettre en place des métriques strictes de validation post-déploiement qui mesurent l'impact réel d'une Pull Request générée, en surveillant non seulement le taux d'erreur, mais également la latence induite et l'empreinte carbone des requêtes exécutées.
Le Piège de la Validation Rapide
Ne validez jamais une Pull Request générée par un agent uniquement parce que les tests unitaires passent. Les agents sont excellents pour écrire du code qui passe les tests qu'ils ont eux-mêmes générés. Exigez des tests d'intégration stricts rédigés par un humain pour encadrer la logique métier critique.
Garde-Fous Automatisés Contre l'Automatisation
Pour survivre à cette escalade, il devient indispensable d'utiliser l'automatisation pour contraindre l'automatisation. Sur le terrain, cela se traduit par l'intégration de moteurs de politiques stricts directement dans vos pipelines de déploiement continu. Ces outils agissent comme une douane impitoyable qui refuse catégoriquement tout code dont l'indice de complexité cyclomatique dépasse un seuil tolérable par le cerveau humain.
En utilisant des solutions comme Open Policy Agent dans vos flux de travail, vous pouvez interdire formellement aux agents de modifier certaines couches vitales de l'infrastructure ou les empêcher de créer des ressources cloud sans l'approbation explicite et vérifiée d'un administrateur senior. L'objectif est de cantonner l'IA aux tâches à faible risque tout en sanctuarisant le cœur de l'architecture.
# Politique OPA pour interdire les augmentations abusives de ressources
package kubernetes.admission
deny[msg] {
input.request.kind.kind == "Deployment"
container := input.request.object.spec.template.spec.containers[_]
memory_limit := container.resources.limits.memory
# Si l'agent tente de provisionner plus de 2Gi sans label d'approbation humaine
endswith(memory_limit, "Gi")
to_number(replace(memory_limit, "Gi", "")) > 2
not input.request.object.metadata.labels["approved-by-human"] == "true"
msg := sprintf("Rejeté : Le conteneur '%v' demande trop de RAM. Validation humaine requise.", [container.name])
}L'Humain au Centre de l'Équation, Plus Que Jamais
En définitive, la génération algorithmique est un outil fantastique qui libère l'ingénieur de la syntaxe pour lui permettre de se concentrer sur la sémantique. Cependant, abandonner notre esprit critique au profit de la vélocité pure est le chemin le plus court vers un désastre opérationnel. Les systèmes que nous construisons aujourd'hui supporteront les entreprises de demain ; ils exigent de la rigueur, de la clarté et une véritable intention architecturale qu'aucune machine ne peut simuler.
Plutôt que d'essayer de concurrencer les agents sur leur propre terrain, revendiquez votre rôle d'architecte et de garant de la stabilité. Utilisez la commande git blame avec fierté, documentez vos choix avec précision dans les fichiers ARCHITECTURE.md et refusez fermement tout code qui nécessite un doctorat en cryptographie pour être lu. La véritable prouesse technique n'est pas d'expédier cent fonctionnalités par jour, mais de concevoir un système tellement élégant qu'un junior rejoignant l'équipe le lundi comprendra l'architecture le vendredi.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
20 commentaires
Le jour où on oubliera de vérifier ce qui est poussé en prod, c'est là qu'on aura vraiment perdu la main. Continuez à exiger de la transparence dans vos pipelines.
Le débat est sain. On a besoin de plus de rigueur. Merci pour le rappel sur l'importance de
git blame. Au moins on sait qui a validé la merde que l'IA a écrite.C'est le genre de situation critique où l'intervention humaine est obligatoire. Une IA n'a pas conscience de la volumétrie de données ou du risque d'interruption de service.
J'ai un collègue qui a laissé une IA gérer ses migrations SQL. Résultat : une table avec 50 millions de lignes bloquée pendant 2h. L'IA a fait un
ALTER TABLEsans réfléchir au verrouillage.C'est une évolution forcée. Soit on accepte de devenir des architectes qui valident des briques, soit on se laisse submerger par la dette technique des agents.
Je suis d'accord avec l'auteur sur le rôle d'auditeur. On devient des relecteurs de code machine. C'est un métier de chiottes, mais c'est la réalité.
Vous parlez beaucoup de code, mais quid de la doc ? L'IA génère des commentaires inutiles type
// Increment i by 1. C'est du bruit qui pollue les fichiersARCHITECTURE.md.Exactement. C'est une discipline. Si tu n'as pas de politique de labels stricte, ton infrastructure devient ingouvernable, IA ou pas.
J'ai testé OPA comme suggéré dans l'article. C'est pas mal pour bloquer les
MemoryPressure, mais il faut bien configurer les labels sinon tout le pipeline plante. Voici mon bloc de test :Le vrai danger, c'est quand l'IA commence à générer ses propres tests unitaires. Elle teste ce qu'elle a codé, donc ça passe toujours au vert. C'est une boucle de feedback biaisée.
C'est le syndrome de la "sécurité par l'excès". L'IA essaie d'être prévisible pour éviter les crashs, mais elle ignore totalement la gestion de la charge réelle du cluster.
Auditer du code généré, c'est parfois plus long que de l'écrire soi-même. Surtout quand c'est verbeux pour rien. Regardez cet exemple de ce qu'une IA m'a sorti pour une simple config :
C'est du grand n'importe quoi, pourquoi forcer les limites à être égales aux requests ?
Le problème c'est qu'on ne peut pas arrêter le progrès. L'IA fait partie du workflow. Il faut apprendre à auditer ce qu'elle sort plutôt que de faire l'autruche.
Perso, j'ai banni l'usage d'agents autonomes sur le cluster. Je préfère un bon vieux
kubectl applyfait par un humain après une revue de code sérieuse.OPA c'est bien, mais c'est encore une usine à gaz à maintenir. Vous n'avez pas peur de créer une dette technique sur l'outillage de sécurité lui-même ?
C'est pour ça que je pousse pour des outils comme OPA. Si tu ne limites pas la machine, elle va s'auto-alimenter en mauvaises pratiques. Il faut imposer des garde-fous au niveau du pipeline.
Moi ce qui m'inquiète, c'est la complexité cyclomatique. L'IA génère des fonctions de 300 lignes avec des imbrications de fou. Comment tu débogues ça quand ça
segfaulten production ?Totalement d'accord avec l'auteur. Le coup de l'augmentation automatique de la RAM en cas de fuite mémoire, j'ai vu ça en prod le mois dernier. C'est le meilleur moyen de cramer ton budget AWS en 24h.
C'est exactement mon point. Le souci, c'est que l'IA baisse la barrière à l'entrée et donne l'illusion de compétence. On se retrouve avec des juniors qui valident des PRs générées sans même comprendre pourquoi il y a une IP codée en dur.
Encore un article qui enfonce des portes ouvertes. Le problème c'est pas l'IA, c'est les devs qui savent pas coder et qui cherchent une béquille. Si tu comprends pas ton
deployment.yaml, tu devrais pas avoir accès au repo, point barre.