L'hégémonie de l'orchestrateur face au mur de la performance
La standardisation absolue des infrastructures a un prix, et l'industrie technologique commence à en mesurer l'ampleur face à l'émergence des charges de travail analytiques massives. Depuis des années, Kubernetes s'est imposé comme le standard de facto pour gérer nos applications conteneurisées, promettant une abstraction universelle des ressources. Pourtant, lorsqu'il s'agit de traiter des milliards de paramètres en temps réel pour l'intelligence artificielle, cette couche d'abstraction universelle devient soudainement un goulot d'étranglement majeur. Les ingénieurs déploient des clusters entiers pour faire tourner des modèles qui requièrent avant tout un accès direct et sans latence aux puces graphiques.
Pour bien comprendre le problème, il faut revenir à l'essence même de l'Orchestration de conteneurs, un concept pensé pour maintenir en vie des microservices web hautement disponibles et interconnectés. Ce paradigme implique une communication constante entre les nœuds, des boucles de réconciliation infinies et une gestion d'état complexe via des bases de données de configuration distribuées. Concrètement, cette machinerie byzantine consomme une part non négligeable de la puissance de calcul brute uniquement pour se maintenir à flot, ce qui entre en contradiction frontale avec la nature éphémère et extrêmement gourmande des entraînements de réseaux neuronaux. Par conséquent, de nombreuses équipes commencent à remettre en question l'utilisation systématique de cette usine à gaz pour des tâches qui nécessiteraient plutôt une autoroute dégagée vers le matériel.
C'est précisément dans ce contexte de friction architecturale que de nouvelles voix s'élèvent pour proposer des solutions radicalement différentes, privilégiant des temps de démarrage de l'ordre de la milliseconde. L'objectif n'est plus de gérer finement le cycle de vie d'un serveur web statique, mais d'allouer dynamiquement des milliers de cœurs de calcul de manière éphémère avant de les détruire tout aussi rapidement. Non seulement cette évolution redéfinit la manière dont nous pensons nos déploiements, mais elle nous force également à réévaluer nos outils d'automatisation traditionnels pour ne conserver que l'essentiel vital à l'exécution du code.
Le syndrome de la complexité byzantine et ses limites
Le paradoxe actuel de nos architectures modernes réside dans la multiplication des couches intermédiaires censées simplifier le travail des développeurs, tout en masquant une fragilité opérationnelle croissante. En ajoutant des opérateurs personnalisés, des contrôleurs d'ingress tentaculaires et des maillages de services pour chaque application, le plan de contrôle gonfle jusqu'à devenir un point de défaillance critique redouté par les administrateurs systèmes. Face à un modèle d'apprentissage profond qui a besoin de saturer la bande passante mémoire d'une carte graphique, chaque milliseconde perdue par l'orchestrateur à interroger son état interne est une perte financière sèche et une inefficacité énergétique inacceptable.
Afin de garantir des déploiements fluides, la plupart des équipes s'appuient sur une CI/CD, cette méthodologie essentielle d'intégration et de livraison continues qui permet de tester et de propager le code en production automatiquement. Cependant, adapter ces pipelines linéaires pour forcer l'orchestration de modèles d'intelligence artificielle via des manifestes déclaratifs rigides relève souvent du bricolage empirique. Les temps de construction des images explosent, le transfert de gigaoctets de poids synaptiques fige les réseaux internes, et la boucle de rétroaction rapide, censée être le cœur de la méthodologie DevOps, se retrouve complètement asphyxiée par la lourdeur du processus de déploiement.
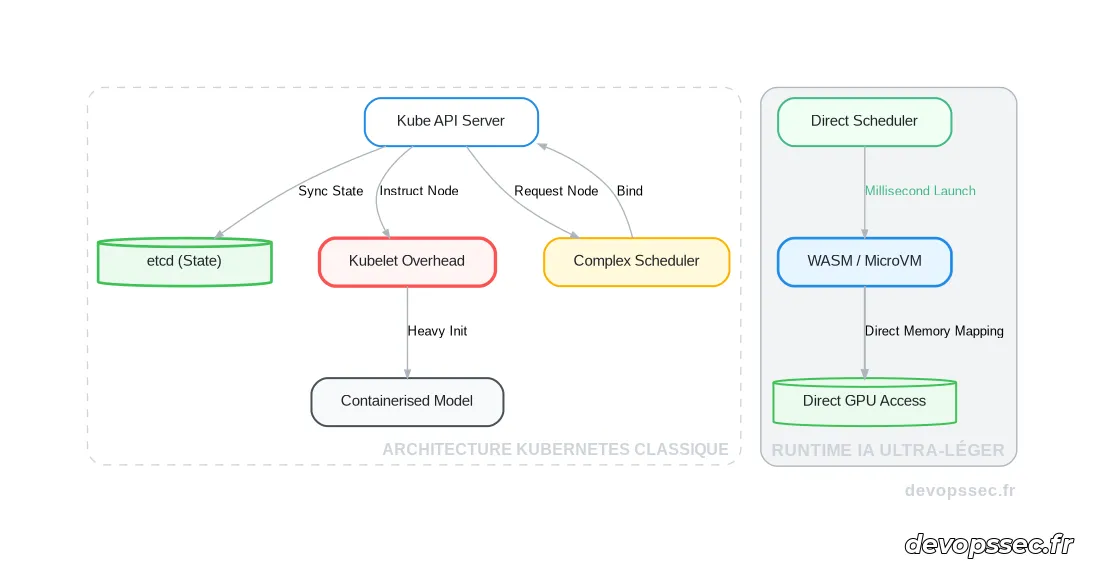
Il devient alors impératif de surveiller finement ces goulets d'étranglement avec une rigueur analytique poussée. C'est ici qu'intervient l'Observabilité, une pratique technique vitale consistant à corréler les journaux d'événements, les métriques d'utilisation et les traces distribuées pour comprendre de l'intérieur le comportement d'un système opaque. Néanmoins, collecter ces données depuis des centaines de conteneurs de courte durée génère un volume d'informations souvent supérieur à celui généré par l'application elle-même, forçant les entreprises à déployer des infrastructures de surveillance presque aussi colossales que leurs environnements de production initiaux.
La désillusion de l'abstraction matérielle
Lorsque l'on manipule des puces spécialisées telles que les unités de traitement tensoriel, la couche réseau virtuelle imposée par l'orchestrateur traditionnel ajoute une latence dommageable. L'utilisation d'interfaces réseau conteneurisées implique des opérations d'encapsulation et de décapsulation constantes des paquets de données. Or, pour des algorithmes massivement parallèles qui s'échangent des matrices de poids en permanence, cette surcharge de traitement CPU devient rapidement un frein inhérent à l'architecture même, empêchant le matériel d'atteindre son rendement théorique maximal.
Pour pallier ces déficiences, les administrateurs ont recours à des rustines techniques complexes, notamment via l'injection de privilèges avancés au sein des manifestes de déploiement. En utilisant des commandes telles que kubectl apply -f config-gpu.yaml, on contraint l'orchestrateur à percer des trous de sécurité dans son propre modèle d'isolation pour offrir un accès direct aux pilotes matériels sous-jacents. Cette démarche remet en cause l'intérêt même d'utiliser un environnement hermétique, transformant l'infrastructure en une chimère difficilement maintenable et hautement vulnérable aux instabilités du noyau système.
| Critère Technique | Orchestrateur Classique | Runtime IA Spécifique |
|---|---|---|
| Temps de démarrage | Quelques secondes à plusieurs minutes | Inférieur à 50 millisecondes |
| Consommation du Plan de Contrôle | Élevée (Bases de données distribuées, multiples démons) | Minimale (Architecture Peer-to-Peer ou décentralisée) |
| Accès Matériel (GPU/TPU) | Via plugins de périphériques complexes | Accès direct natif ou mapping mémoire optimisé |
| Complexité des Manifestes | YAML byzantin et verbeux | Déclarations simples et paramétrage direct |
De plus, l'allocation des ressources souffre d'un manque criant de flexibilité granulaire face aux charges de travail imprévisibles. Le planificateur par défaut assigne les tâches en fonction de réservations CPU et mémoire statiques définies en amont, une approche totalement inadaptée pour des algorithmes dont la consommation explose par pics lors des phases d'inférence complexes. Les développeurs se retrouvent ainsi forcés de sur-allouer massivement leurs ressources matérielles pour éviter les arrêts brutaux, gaspillant au passage des milliers de dollars en puissance de calcul inutilisée la majeure partie du temps.
L'émergence des alternatives et l'exécution ultra-légère

Face à cette impasse architecturale, le marché observe un pivot stratégique vers des technologies qui privilégient l'isolation pure sans le fardeau de l'orchestration complète. C'est dans cette brèche que s'engouffre WebAssembly (WASM), un format d'instruction binaire originellement conçu pour les navigateurs, mais qui révolutionne désormais les environnements serveurs grâce à sa sécurité intrinsèque et sa vitesse d'exécution quasi instantanée. En encapsulant les logiques métier dans des modules WASM extrêmement compacts, les ingénieurs peuvent déclencher des calculs intensifs sur n'importe quelle architecture matérielle en s'affranchissant totalement des démons de conteneurisation habituels.
Concrètement, cette approche modifie radicalement le chemin critique du développement vers la production. Au lieu de compiler des images de plusieurs centaines de mégaoctets contenant un système d'exploitation complet, les équipes génèrent des binaires d'à peine quelques kilo-octets. Ces modules sont ensuite exécutés par des planificateurs minimalistes, tels que Nomad ou des moteurs d'inférence spécialisés, capables de distribuer des milliers de requêtes par seconde avec une empreinte mémoire dérisoire. Par conséquent, la densité d'exécution sur un même cluster physique est décuplée, maximisant le retour sur investissement des infrastructures matérielles les plus coûteuses.
La nécessaire évaluation des risques d'une migration
Pourtant, prôner la sortie abrupte des standards de l'industrie n'est pas une décision à prendre à la légère, car le démantèlement d'un écosystème mature cache souvent des pièges opérationnels majeurs. L'abandon d'une plateforme mondialement documentée signifie la perte instantanée d'un maillage d'outils de sécurité, de gestion des secrets et de sauvegarde que la communauté a mis des années à fiabiliser. Adopter un orchestrateur de niche ou un moteur d'exécution novateur implique souvent de devoir recoder soi-même les intégrations de routage réseau ou de persistance des données qui fonctionnaient nativement auparavant.
Le mirage de la performance absolue
Avant de migrer vos charges de travail hors de votre environnement conteneurisé classique, profilez vos applications. Dans 80% des cas, la latence perçue provient d'un code applicatif non optimisé ou de requêtes inefficaces en base de données, plutôt que de l'overhead de l'orchestrateur réseau lui-même.
Sur le plan de la sécurité, les runtimes ultra-légers introduisent de nouveaux vecteurs d'attaque qu'il convient de maîtriser avec la plus grande prudence. Bien que les modules binaires promettent une isolation par bac à sable rigoureuse, les interfaces permettant la communication directe avec le matériel physique ou les processeurs graphiques constituent des ponts critiques vulnérables aux débordements de mémoire. Les administrateurs doivent redoubler de vigilance et implémenter des politiques de restriction drastiques au niveau de l'hôte, augmentant ainsi paradoxalement la charge cognitive des équipes de sécurité internes.
Illustrons cette réalité opérationnelle en comparant un déploiement traditionnel lourd avec une exécution directe en ligne de commande. Dans une approche classique, l'équipe d'infrastructure doit maintenir un manifeste déclaratif complexe, spécifiant les limites, les tolérances et les affinités des nœuds matériels. La configuration requise dans un environnement standard nécessite la création d'un fichier hébergé dans /deployments/manifests/ avec une structure profondément imbriquée.
apiVersion: apps/v1
kind: Deployment
metadata:
name: model-inference
spec:
replicas: 3
selector:
matchLabels:
app: ai-worker
template:
metadata:
labels:
app: ai-worker
spec:
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: worker
image: custom-registry/ai-model:latest
resources:
limits:
nvidia.com/gpu: 1
memory: "64Gi"En contraste frappant, l'utilisation d'un planificateur minimaliste permet de déclencher l'exécution du même algorithme via une commande impérative ou un script simplifié, réduisant drastiquement l'enrobage administratif. L'ingénieur peut alors invoquer directement le binaire pré-compilé et laisser le runtime allouer la mémoire physique disponible instantanément, offrant une flexibilité redoutable lors des phases de prototypage ou d'ajustement des hyperparamètres. L'exécution d'une commande telle que wasmtime run --gpu-access model.wasm démontre cette simplicité frontale.
nomad run ./jobs/ai-inference-fast.nomad
nomad status ai-inference-fastRésultat:
==> Monitoring evaluation "e7f8a9"...
Evaluation status changed: "Pending" -> "Complete"
==> Evaluation "e7f8a9" finished with status "complete"
Allocations created: 1
Deployment ID: d-89b12c
Status: Running (Deployed in 45ms)
Hardware Bound: GPU-Node-03 (Direct Access Enabled)Vers une cohabitation stratégique plutôt qu'une rupture
En définitive, la diabolisation de nos outils d'orchestration historiques face aux nouvelles exigences de la donnée massive manque cruellement de nuance opérationnelle. L'usine à gaz tant décriée reste un chef-d'œuvre d'ingénierie logicielle incontournable pour maintenir la résilience des architectures web asynchrones, gérer les bases de données distribuées et orchestrer le trafic mondial des API de nos entreprises. Le véritable défi de cette nouvelle ère technologique n'est pas de détruire les fondations existantes, mais d'accepter que le modèle unique et universel a vécu, ouvrant la voie à une approche beaucoup plus pragmatique de nos infrastructures.
L'avenir appartient aux ingénieurs capables de concevoir des architectures hybrides, où un plan de contrôle robuste gère les services transverses classiques, tout en déléguant intelligemment les charges de travail intensives à des moteurs d'exécution spécifiques et ultra-légers. C'est dans cette hybridation fine, couplant la fiabilité de l'orchestration déclarative avec la fulgurance d'un accès matériel direct, que réside l'élégance d'une ingénierie moderne performante. Apprendre à utiliser le bon outil pour le bon contexte technique, sans succomber aux sirènes de la nouveauté absolue ou au dogme de la standardisation forcée, reste la compétence la plus précieuse que vous puissiez cultiver dans votre parcours technique.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
18 commentaires
Belle analyse !
Si votre équipe est assez grande pour gérer la complexité d'un cluster, elle est assez grande pour isoler le compute. N'ayez pas peur de sortir du cadre quand le besoin de performance est réel et documenté.
L'hybridation, c'est deux fois plus de tech à maintenir. Pour une petite équipe, c'est la mort assurée. Restons sur K8s, c'est standard, c'est solide, et on sait gérer les
tolerationspour les GPUs.Je ne compare pas des Ferrari, je compare des outils de transport. Si tu as juste besoin de déplacer un colis lourd (données ML), un camion (orchestrateur lourd) est moins efficace qu'un transport dédié. L'hybridation est la clé.
Le problème de l'auteur, c'est qu'il compare une architecture de production mature avec un POC impératif. C'est comparer une Ferrari avec un moteur de tondeuse : ça va plus vite, mais ça ne transporte personne.
Franchement, le
deployment.yamlcité en exemple n'est pas si horrible que ça. C'est standard, tout le monde sait le lire. Pourquoi vouloir le remplacer par des scripts impératifs qui ne laissent aucune trace dans le versioning ?L'observabilité est un sujet complexe, certes. Mais corréler des traces sur 100 microservices via un Service Mesh, c'est aussi un coût caché massif en latence et en complexité opérationnelle.
Le coût de l'observabilité est souvent ignoré dans ces comparatifs. Si tu économises sur le compute mais que tu passes 2 jours de dev par mois à maintenir ton propre monitoring, le ROI est négatif.
J'ai testé l'approche décrite dans l'article pour un pipeline d'inférence. On a utilisé une commande simple au lieu d'un gros bloc YAML :
C'est radicalement plus rapide, mais le monitoring est devenu un cauchemar. On a dû recoder une stack entière avec Prometheus pour voir ce qui se passait.
Le "support de la communauté" ne paiera pas votre facture cloud quand vous aurez 30% de CPU gaspillé par les boucles de réconciliation de l'orchestrateur. Il faut savoir choisir ses combats.
Le souci, c'est que dès que tu sors des sentiers battus, tu perds le support de la communauté. Si tu as un bug avec ton runtime custom, tu es seul au monde.
C'est marrant cette fascination pour Nomad. On a quitté Consul/Nomad pour K8s il y a 4 ans parce que la gestion des secrets était un enfer. Vous proposez quoi pour remplacer
SecretetConfigMapsans tout réinventer ?C'est justement là que Nomad ou WASM brillent. On n'est pas obligés de tout porter, on isole juste la partie compute intensive. Personne ne dit de jeter tout le cluster, mais arrêtez de mettre vos workers GPU dans le même
Deploymentque votre API front-end.Exact. Et puis, parler de
wasmtimecomme solution universelle, c'est oublier que la majorité des libs de ML sont en C++ ou Python avec des bindings complexes. Bon courage pour porter ça proprement.Le problème c'est pas l'orchestrateur, c'est l'usage des
resources: limitsdans le YAML. Si tu configures mal tes requests, le kernel te throttle et tu penses que c'est Kubernetes qui est lent. C'est une erreur classique de débutant.Je ne dis pas que c'est simple, je dis que le surcoût de l'orchestrateur pour du calcul pur est absurde. Quand ton modèle IA prend 3 secondes à démarrer juste parce que le scheduler vérifie l'état de 500 pods, tu comprends que l'abstraction a un prix.
Complètement d'accord. L'auteur parle de "complexité byzantine" mais il oublie que cette complexité, c'est ce qui évite de gérer les secrets et les politiques réseau à la main.
kubectl apply, c'est peut-être verbeux, mais au moins c'est auditable.Encore un article qui vend du rêve avec le WASM. Vous avez déjà essayé de debugger une stack réseau complexe dans un environnement WASM sans les outils standard comme
tcpdumpounetstat? C'est le retour à l'âge de pierre.