Révolutionnez vos tests et l'IA avec les Données Synthétiques
Vous est-il déjà arrivé de bloquer le déploiement d'une fonctionnalité cruciale par manque de données de test pertinentes ? Ou pire, d'utiliser des scripts d'anonymisation fragiles, en espérant ne jamais exposer une information client sensible ? Cette tension permanente entre le besoin de réalisme et l'impératif de sécurité est un défi quotidien en DevOps.
Pourtant, une approche change radicalement la donne en dissociant la structure de l'information de sa substance confidentielle. Il s'agit des données synthétiques, des données créées artificiellement qui imitent à la perfection les propriétés statistiques et les schémas de vos données de production, sans contenir la moindre information réelle.
Le rôle des données synthétiques dans un pipeline CI/CD moderne
Intégrer la génération de données synthétiques n'est pas un simple ajout à votre boîte à outils c'est une refonte philosophique de la manière dont vous gérez les environnements de non-production. Au lieu de dépendre de "dumps" de base de données lourds, complexes à nettoyer et risqués, vous produisez des données fraîches, propres et sécurisées à la demande, directement dans votre flux de travail automatisé.
Concrètement, la chaîne d'outils s'enrichit d'un nouveau maillon : un service de génération de données. Ce service, piloté par une configuration déclarative, devient une étape à part entière de votre pipeline, aussi naturelle que la compilation du code ou le lancement des tests unitaires. Il assure que chaque environnement de test ou de pré-production est peuplé avec un jeu de données parfaitement adapté au besoin du moment.
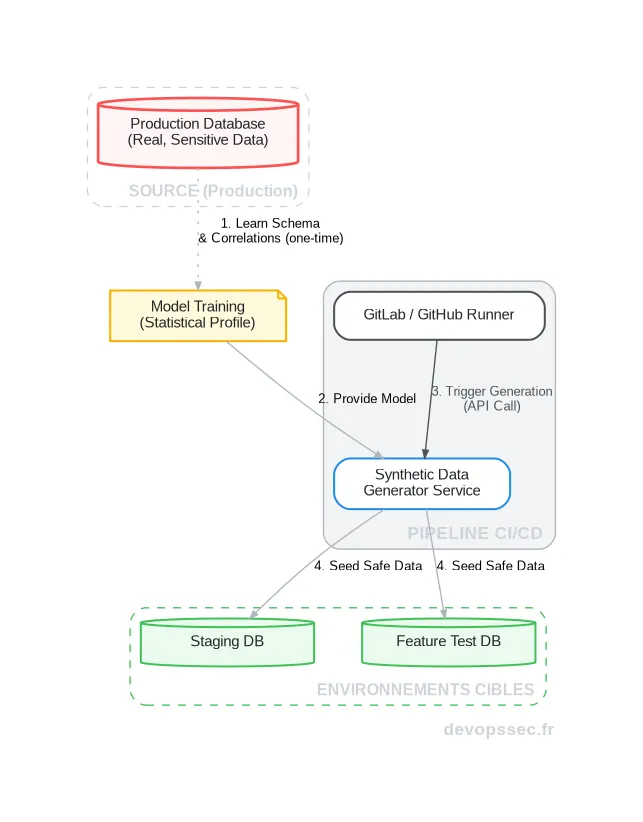
Ce schéma illustre parfaitement le cycle de vie. Une première phase d'apprentissage (réalisée une seule fois ou périodiquement) analyse la structure et les relations de vos données réelles pour créer un modèle statistique. Ensuite, votre pipeline CI/CD, via un runner, appelle le service de génération qui utilise ce modèle pour produire et injecter des données fraîches et sécurisées dans les bases de données de Staging ou de test, à chaque exécution.
La configuration déclarative au cœur du processus
L'un des plus grands atouts de cette approche est qu'elle s'inscrit parfaitement dans la logique de l'Infrastructure as Code (IaC). La "forme" de vos données est décrite dans des fichiers de configuration versionnés, tout comme le reste de votre application. Cela garantit la reproductibilité et la traçabilité des jeux de données utilisés pour chaque test.
Imaginez un fichier config.yaml qui définit les tables, les colonnes, les types de données (email, numéro de téléphone, adresse IP) et même les relations complexes entre les entités. C'est ce fichier qui devient la source de vérité pour la génération.
# Exemple de configuration pour un générateur de données synthétiques
version: 1.0
schema:
users:
count: 1000
columns:
- name: id
type: incrementing_id
- name: email
type: email_address
domain: "synthetic-users.dev"
- name: created_at
type: datetime_between
start_date: "-2y"
end_date: "now"
- name: last_ip
type: ipv4
orders:
count: 5000
columns:
- name: order_id
type: uuid
- name: user_id
type: foreign_key
references: users.id # Maintient l'intégrité référentielle
- name: amount
type: float
min: 10.0
max: 500.0
precision: 2Automatiser l'injection dans les tests d'intégration
Une fois la configuration établie, l'intégration dans le pipeline devient un jeu d'enfant. Un job dédié peut être ajouté à votre fichier .gitlab-ci.yml ou à un workflow GitHub Actions. Ce job se charge de déclencher le générateur et d'utiliser sa sortie pour peupler une base de données éphémère, souvent lancée via Docker.
Le piège de la performance
Attention, la génération de gros volumes de données peut ralentir votre pipeline. Une bonne pratique consiste à générer un jeu de données de référence une seule fois, le stocker dans un artefact, et le réutiliser pour les tests qui ne modifient pas les données. La génération à la volée doit être réservée aux tests qui nécessitent une fraîcheur absolue.
Le script d'un tel job pourrait ressembler à ceci, illustrant l'enchaînement des commandes : démarrer la base de données, générer les données et les injecter.
# Étape dans un pipeline CI pour peupler une base de données de test
echo "🚀 Starting test database..."
docker run --name test-db -e POSTGRES_PASSWORD=secret -d postgres:15
echo "🧬 Generating synthetic data..."
synthetic-data-cli generate --config ./config/schema.yaml --output data.sql
echo "💉 Seeding database..."
sleep 5 # Laisser le temps à la base de démarrer
cat data.sql | docker exec -i test-db psql -U postgres
echo "✅ Database is ready for integration tests!"Résultat:
🚀 Starting test database...
[Docker container hash]
🧬 Generating synthetic data...
Generated 1000 users and 5000 orders. Output saved to data.sql.
💉 Seeding database...
psql:stdin: ...
✅ Database is ready for integration tests!Au-delà des tests : l'entraînement des modèles d'IA
L'impact des données synthétiques ne s'arrête pas aux tests logiciels. Il s'étend de manière spectaculaire au domaine de l'intelligence artificielle et du machine learning. Entraîner des modèles performants nécessite des volumes de données massifs et variés, ce qui pose souvent des problèmes de disponibilité, de coût et, encore une fois, de confidentialité.
Les données synthétiques permettent de surmonter ces obstacles en créant des jeux de données d'entraînement enrichis, équilibrés et parfaitement anonymes. C'est un véritable accélérateur pour l'innovation, en particulier dans des secteurs ultra-réglementés comme la santé ou la finance.
| Scénario d'entraînement IA | Problématique des données réelles | Avantage des données synthétiques |
|---|---|---|
| Modèle de détection de maladies rares | Très peu d'exemples disponibles (dataset déséquilibré) | Possibilité de sur-échantillonner les cas rares pour créer un jeu de données équilibré et améliorer la performance du modèle. |
| Développement d'un véhicule autonome | Difficile de collecter des données sur des scénarios dangereux (accidents, météo extrême) | Génération de milliers de scénarios de "edge cases" pour rendre l'IA plus robuste face à l'imprévu. |
| Analyse de sentiment sur des avis clients | Les données contiennent des informations personnelles identifiables (noms, adresses). | Création d'un corpus de texte qui conserve le style, le ton et le vocabulaire sans exposer la moindre donnée privée. |
Les limites et les risques à ne pas ignorer
Malgré leurs avantages évidents, les données synthétiques ne sont pas une solution miracle. Leur mise en œuvre requiert une compréhension fine des enjeux et des technologies sous-jacentes, car une mauvaise utilisation peut conduire à un faux sentiment de sécurité.
La fidélité du modèle de génération
Le principal défi réside dans la qualité du modèle de génération. Si le modèle ne capture pas correctement les corrélations complexes et les distributions subtiles des données originales, les données synthétiques générées seront de piètre qualité. Elles ne représenteront pas la réalité, et les tests effectués sur ces données pourraient ne pas détecter de véritables bugs.
Des modèles sophistiqués comme les GANs (Generative Adversarial Networks) offrent une fidélité impressionnante mais sont complexes à mettre en œuvre et gourmands en ressources de calcul. Choisir le bon outil et le bon modèle est donc un compromis permanent entre fidélité, coût et complexité.
Les coûts de calcul et de maintenance
Intégrer une étape de génération de données dans un pipeline CI/CD n'est pas neutre. Selon le volume et la complexité, cette étape peut ajouter de précieuses minutes à chaque exécution, impactant la productivité des équipes de développement. Il est donc crucial d'optimiser ce processus, par exemple en utilisant des artefacts ou en parallélisant les tâches.
De plus, le modèle de génération doit être maintenu. Si le schéma de votre base de données de production évolue, le modèle doit être ré-entraîné pour que les données synthétiques continuent de refléter la réalité. Cet effort de maintenance ne doit pas être sous-estimé.
Prêt à synthétiser l'avenir de vos données ?
Vous l'aurez compris, les données synthétiques ne sont plus un concept de laboratoire réservé aux chercheurs en IA. Elles représentent une évolution pragmatique et nécessaire pour tout écosystème DevOps soucieux de vitesse, de qualité et de sécurité. Elles résolvent le paradoxe fondamental qui consiste à avoir besoin de données qui ressemblent à la production sans jamais utiliser la production elle-même.
En adoptant cette approche, non seulement vous protégez les informations de vos utilisateurs et vous vous conformez aux régulations les plus strictes, mais vous donnez aussi à vos équipes les moyens d'innover plus vite. Que ce soit pour tester une nouvelle fonctionnalité, évaluer la performance d'une requête SQL ou entraîner un algorithme de machine learning, vous disposez d'une source de données illimitée, flexible et entièrement sécurisée.
Alors, la prochaine fois que vous hésiterez à lancer un test de charge par peur d'impacter la production, demandez-vous si le moment n'est pas venu de commencer à générer votre propre réalité.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
27 commentaires
Dernier point : ne sous-estimez pas le besoin de nettoyer les bases après les tests. Utilisez des conteneurs éphémères pour ne jamais laisser de résidus.
Absolument. Tu peux générer des lignes de logs structurées. C'est même idéal pour stresser ton pipeline de parsing sans polluer ton index de prod.
Est-ce que ça peut générer des données de logs aussi ? Pour tester notre stack ELK ?
Oublie les GANs si tu n'as pas une équipe dédiée. Utilise des générateurs basés sur des règles (Faker, etc.) combinés à des contraintes SQL.
C'est largement suffisant pour 90% des cas d'usage DevOps.
La maintenance des modèles GANs, c'est vraiment l'enfer. Vous avez des retours sur des alternatives plus simples ?
Oui, parce que tu peux injecter des données 'malveillantes' volontairement dans ton jeu de données pour vérifier que tes filtres de sécurité tiennent le choc.
Et pour les tests de sécurité (injection, etc.), ça aide vraiment d'avoir des données synthétiques ?
Ça dépend. Si tu es sur du Kubernetes avec des runners éphémères, c'est propre. Évite juste de monter des volumes persistants inutiles.
Le
docker rundans le pipeline, c'est pas trop lourd en termes de ressources runner ?On utilise des outils de profiling de données simples. On compare les histogrammes des colonnes clés avec un petit script Python.
Vous utilisez quels outils pour comparer la distribution des données synthétiques vs réelles ?
Versionne ton
config.yamlavec le code de ton application. Si tu changes la table, tu changes le YAML dans la même PR.Si la CI casse, c'est que ton générateur n'est plus synchro avec ton schéma de BDD.
C'est quoi la meilleure stratégie pour maintenir ces scripts de génération quand le schéma SQL change tous les quatre matins ?
Il faut injecter des distributions statistiques réelles dans ton générateur. Si tu as une distribution de Pareto sur tes commandes, ton
config.yamldoit le refléter.Ne génère pas 1000 lignes au hasard, injecte les poids réels.
J'ai testé, mais mes tests de perf sont biaisés car les données synthétiques n'ont pas la même cardinalité que la prod. Une idée pour corriger ça ?
Carrément. Le format de sortie change juste de
data.sqlvers dujson. Le principe de config reste identique.Ça marche aussi pour les bases NoSQL type MongoDB ?
Il existe plusieurs libs en Python ou Go. L'essentiel est que le parser construise un DAG (Directed Acyclic Graph) des dépendances avant de générer quoi que ce soit.
Le concept de
foreign_keydans le YAML est super pratique. Vous utilisez quel outil pour parser ça ?Le risque zéro n'existe pas, surtout avec des modèles ML type GANs qui peuvent mémoriser des données d'entraînement.
La solution : utilise des générateurs basés sur des règles métier plutôt que du pur machine learning si tu as besoin d'une garantie totale de non-exposition.
On fait comment pour les données sensibles de type RGPD ? Est-ce qu'on est sûr à 100% qu'un modèle de génération ne peut pas fuiter une info réelle ?
Bien vu. Le
sleepest là pour la lisibilité de l'exemple, mais en prod, ne fais jamais ça.Utilise une boucle d'attente avec
pg_isreadyou un healthcheck Docker pour être sûr que le port est vraiment ouvert.Le coup du
sleep 5dans le script pour attendre Postgres, c'est un peu sale non ? Pourquoi pas unpg_isready?C'est là que la config déclarative montre ses limites si l'outil est basique. Il faut un moteur capable de gérer le graphe de dépendances.
Si ton outil ne gère pas les relations, tu dois découper ton
config.yamlen étapes pour peupler les tables parents avant les enfants.Comment tu gères les contraintes de clés étrangères complexes ? Dans mon projet, j'ai des relations circulaires et le générateur finit toujours par planter.