Io_uring : Le chaînon manquant des I/O

Pendant des décennies, l'écosystème Linux a reposé sur des primitives d'I/O bloquantes ou semi-asynchrones qui, sous une charge extrême, finissent inévitablement par s'effondrer sous le poids de leur propre conception. Si epoll a permis l'avènement de serveurs hautement concurrents, l'arrivée de périphériques de stockage ultra-rapides et de cartes réseau à très haut débit a mis en lumière un goulet d'étranglement insoupçonné : le coût exorbitant de l'appel système traditionnel.
C'est pour briser ce plafond de verre que io_uring a été introduit par Jens Axboe. Cette interface révolutionnaire propose de repenser intégralement le dialogue entre vos applications et le noyau en éliminant presque entièrement la nécessité d'effectuer des transitions coûteuses vers le mode noyau pour chaque opération d'I/O.
Genèse et fondations système de io_uring

Le fardeau des appels système traditionnels
Pour comprendre la genèse de io_uring, il faut analyser le comportement du système d'exploitation lors d'une lecture de fichier standard. Chaque appel à la fonction read() ou write() force le processeur à exécuter un changement de contexte, une opération complexe qui suspend l'exécution du code de votre application pour donner le contrôle au noyau Linux. Imaginez un employé de bureau qui, pour chaque lettre à envoyer, doit s'arrêter de travailler, traverser tout le bâtiment pour la donner en main propre au directeur, et attendre son retour pour reprendre sa tâche ; c'est précisément ce que subit votre CPU lors de transferts intensifs.
Cette friction s'est dramatiquement intensifiée avec les correctifs de sécurité contre les vulnérabilités du processeur. Ces correctifs imposent une isolation stricte des tables de pages du noyau (KPTI), doublant parfois le coût d'une simple transition de mode. L'ancienne API asynchrone Linux AIO, quant à elle, souffrait de limitations majeures : elle ne fonctionnait que sur des fichiers ouverts avec le drapeau O_DIRECT, bloquait fréquemment si les métadonnées n'étaient pas en cache, et s'avérait inutilisable sur les sockets réseau.
Les prérequis système et noyau
Pour exploiter pleinement la puissance de io_uring, un noyau Linux moderne est requis. Bien que l'interface ait été introduite dans la version 5.1, il est vivement recommandé d'utiliser au minimum un noyau Linux 5.10 LTS ou supérieur, les premières itérations ayant souffert de quelques limitations fonctionnelles et de sécurité importantes.
Sur le plan des configurations système, l'administrateur système doit s'assurer que les limites de mémoire verrouillée (RLIMIT_MEMLOCK) sont configurées de manière adéquate dans le fichier /etc/security/limits.conf. En effet, io_uring doit verrouiller des pages de mémoire physique pour ses structures de données internes afin de s'assurer qu'elles ne soient jamais déplacées vers l'espace d'échange (swap) par le gestionnaire de mémoire virtuelle.
Le fonctionnement interne du Ring Buffer
Le partage de mémoire sans copie
L'architecture de io_uring repose sur un concept fondamental : deux ring buffers (files circulaires) partagés directement entre l'espace utilisateur et l'espace noyau. Ce mécanisme évite de copier inutilement les structures de contrôle d'un espace mémoire à un autre. La première file est la Submission Queue (SQ), où l'application écrit les requêtes d'I/O qu'elle souhaite exécuter, tandis que la seconde est la Completion Queue (CQ), dans laquelle le noyau dépose les résultats une fois les opérations terminées.
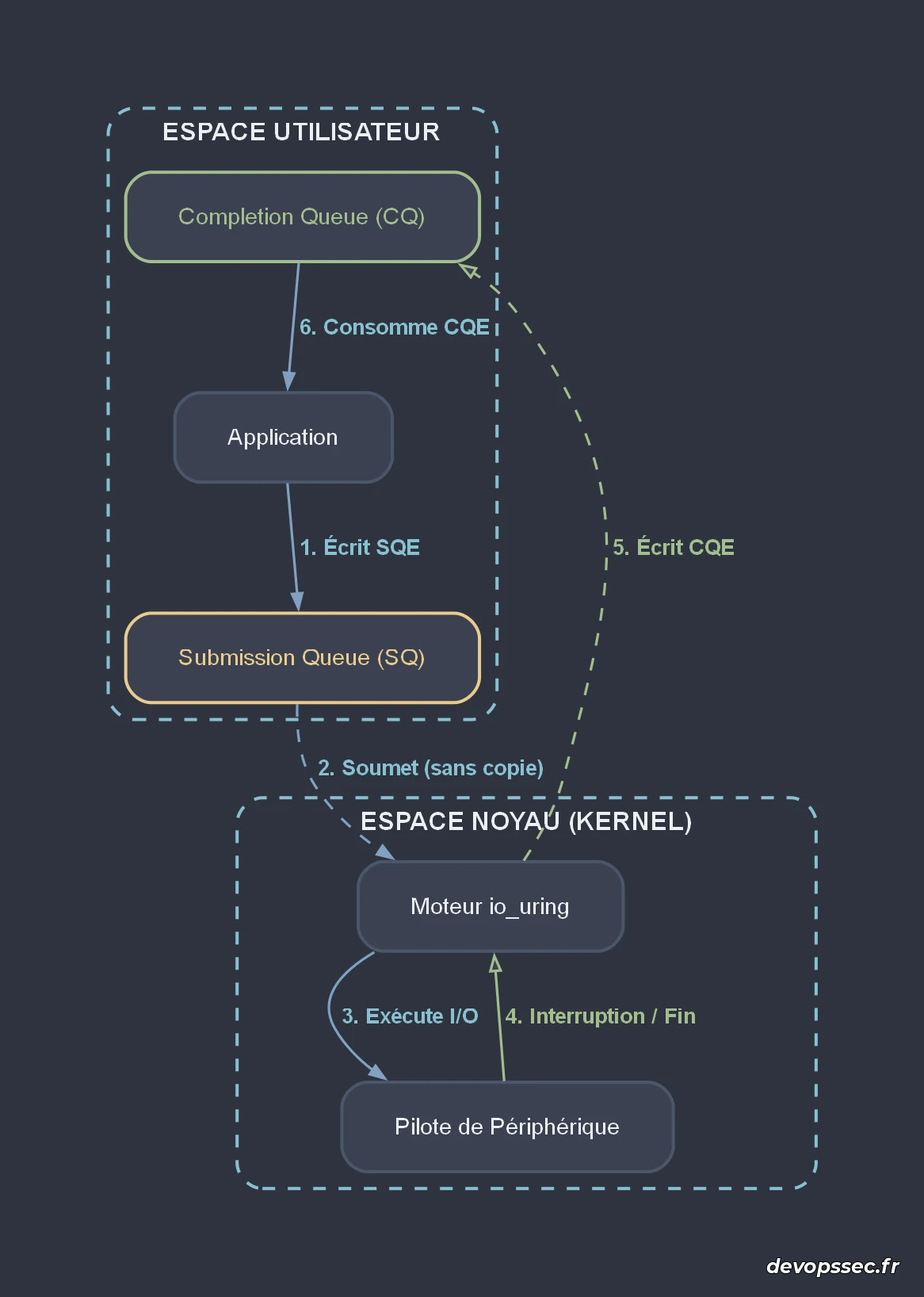
Le schéma ci-dessus illustre la nature asynchrone et découplée de cette architecture. L'application écrit des éléments de file d'attente de soumission (Submission Queue Entries ou SQE) dans la file SQ. Le noyau Linux lit ces entrées directement dans la mémoire partagée, effectue l'opération requise en tâche de fond de manière non bloquante, puis place un élément de file d'attente de complétion (Completion Queue Entry ou CQE) dans la file CQ que l'application peut ensuite lire à son rythme.
Le mode Kernel Polling (SQPOLL)
Bien que le mode de fonctionnement standard réduise drastiquement le nombre d'appels système, l'application doit toujours effectuer un appel à io_uring_enter() pour notifier le noyau qu'elle a déposé de nouvelles requêtes dans la file SQ. Pour éliminer totalement cet ultime appel système, io_uring propose un mode ultra-optimisé appelé Kernel Polling (activable via le drapeau IORING_SETUP_SQPOLL).
Dans ce mode, le noyau démarre un thread d'arrière-plan dédié qui scrute en continu (poll) la file SQ pour y détecter de nouvelles requêtes de manière autonome. L'application se contente d'écrire dans la mémoire partagée et de lire la file CQ, réalisant des opérations d'I/O complexes sans exécuter le moindre appel système.
Attention à la consommation CPU
L'activation du mode SQPOLL consomme un cœur CPU complet dédié au thread de polling du noyau, même si aucune I/O n'est en cours. Ce mode est à réserver exclusivement aux applications réseau ou de stockage à ultra-haute performance qui saturent constamment leurs canaux de transmission.
Cas pratique : Serveur d'I/O asynchrone ultra-optimisé
Mise en œuvre avec liburing
Pour simplifier l'interaction avec les structures de données complexes et éviter la manipulation manuelle des barrières de mémoire, Jens Axboe a développé la bibliothèque liburing. Nous allons étudier un programme C complet conçu pour lire un fichier de manière totalement asynchrone en exploitant les mécanismes internes de io_uring.
#include <stdio.h>
#include <fcntl.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/stat.h>
#include "liburing.h"
#define QUEUE_DEPTH 4
#define BLOCK_SIZE 4096
int main(int argc, char *argv[]) {
struct io_uring ring;
struct io_uring_sqe *sqe;
struct io_uring_cqe *cqe;
struct iovec iov;
int fd, ret;
char *buf;
if (argc < 2) {
fprintf(stderr, "Usage: %s <filename>\n", argv[0]);
return 1;
}
fd = open(argv[1], O_RDONLY | O_DIRECT);
if (fd < 0) {
perror("Erreur d'ouverture du fichier");
return 1;
}
// Allocation d'un tampon aligné sur les blocs pour O_DIRECT
ret = posix_memalign((void **)&buf, BLOCK_SIZE, BLOCK_SIZE);
if (ret) {
perror("Erreur d'allocation mémoire");
close(fd);
return 1;
}
// Initialisation de l'instance io_uring
ret = io_uring_queue_init(QUEUE_DEPTH, &ring, 0);
if (ret < 0) {
fprintf(stderr, "Impossible d'initialiser io_uring: %s\n", strerror(-ret));
free(buf);
close(fd);
return 1;
}
// Préparation de la structure d'E/S vectorielle
iov.iov_base = buf;
iov.iov_len = BLOCK_SIZE;
// Récupération d'une entrée de soumission (SQE)
sqe = io_uring_get_sqe(&ring);
if (!sqe) {
fprintf(stderr, "Impossible de récupérer une SQE\n");
io_uring_queue_exit(&ring);
free(buf);
close(fd);
return 1;
}
// Enregistrement d'une lecture asynchrone
io_uring_prep_readv(sqe, fd, &iov, 1, 0);
// Soumission de la requête et attente bloquante de sa complétion
ret = io_uring_submit_and_wait(&ring, 1);
if (ret < 0) {
fprintf(stderr, "Erreur de soumission: %s\n", strerror(-ret));
io_uring_queue_exit(&ring);
free(buf);
close(fd);
return 1;
}
// Traitement du résultat de l'opération (CQE)
ret = io_uring_wait_cqe(&ring, &cqe);
if (ret < 0) {
fprintf(stderr, "Erreur lors de l'attente de complétion: %s\n", strerror(-ret));
} else {
if (cqe->res < 0) {
fprintf(stderr, "La lecture a échoué: %s\n", strerror(-cqe->res));
} else {
printf("Lecture réussie de %d octets.\n", cqe->res);
}
// Marquer l'événement comme traité
io_uring_cqe_seen(&ring, cqe);
}
// Nettoyage des ressources
io_uring_queue_exit(&ring);
free(buf);
close(fd);
return 0;
}Dans ce segment de code, l'appel à io_uring_queue_init() configure les structures internes en mémoire et mappe les registres nécessaires. L'utilisation du drapeau O_DIRECT combiné à un tampon mémoire aligné garantit que l'I/O court-circuite le cache du système d'exploitation, permettant un transfert direct du périphérique de stockage physique vers notre espace d'adressage sans aucune copie intermédiaire.
Pour analyser les performances de ce type de code sous une charge importante, nous pouvons inspecter l'activité des threads de notre application à l'aide des outils de tracing de performance Linux.
# Commande pour observer les appels système générés par l'application
strace -c ./io_uring_demo /mnt/nvme/test_file.binRésultat:
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
45.12 0.000124 62 2 mmap
32.22 0.000088 88 1 io_uring_setup
22.66 0.000062 62 1 io_uring_enter
------ ----------- ----------- --------- --------- ----------------
100.00 0.000274 4 totalL'observation des résultats du traceur révèle la puissance de l'architecture. Malgré une opération d'I/O complexe, un seul et unique appel système io_uring_enter a été exécuté pour soumettre et récolter le résultat du traitement. En comparaison, une approche classique impliquant des ouvertures, des allocations, des lectures multiples et des synchronisations de métadonnées aurait requis des dizaines d'appels système gourmands en cycles d'horloge.
L'avenir des architectures asynchrones sous Linux
L'intégration de io_uring redéfinit radicalement les bases du développement système et DevOps. En déplaçant la frontière logique des opérations d'I/O du niveau de l'appel système synchrone vers des structures de données partagées, elle permet à vos applications d'exploiter la pleine capacité matérielle moderne sans saturer le processeur avec des changements de contexte incessants.
Adopter ces mécanismes à l'échelle de la production requiert une rigueur d'ingénierie et une compréhension fine du cycle de vie de la mémoire. Néanmoins, l'effort en vaut la chandelle : les gains en termes de densité d'infrastructure, de réduction de la latence de traitement et de débit global font de io_uring un pilier indispensable des systèmes haute performance modernes.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
26 commentaires
Bon courage pour la migration. Vérifie bien tes logs après le premier déploiement, les erreurs de
io_uringsont parfois cryptiques si tu ne checkes pas le code retour decqe->res.Merci pour le retour. Je tente une migration de mon proxy perso avec ça ce week-end.
En Go, tu dois utiliser
unix.Openavec les flags adéquats. Voici un exemple rapide :C'est quoi la syntaxe pour forcer le buffer en
O_DIRECTsi on utilise la lib en Go ?Tu vas consommer une quantité non négligeable de mémoire non paginable. C'est du verrouillage de pages, donc gaffe à ne pas OOM ton host.
Quel est l'impact sur la consommation mémoire globale du système si on monte les
QUEUE_DEPTHà 65536 ?Tu peux, mais quel est l'intérêt ? Si tu passes sur
io_uring, migre tout ton stack réseau dessus pour unifier ton modèle de programmation.On peut mixer
io_uringavec des sockets non-bloquants classiques ou c'est à ne jamais faire en prod ?Si la
CQest pleine, les nouvelles soumissions échouent. Ton application doit être capable de drainer la file rapidement pour éviter ce bouchon.Sympa le schéma, mais en cas de saturation de la
CQ, le noyau bloque ou il rejette les nouvelles entrées ?La
liburings'occupe des barrières de mémoire pour toi. C'est l'intérêt d'utiliser la lib plutôt que de manipuler les structures mémoire à la main.J'ai une question sur les barrières mémoire. Dans le code, est-ce que
io_uring_get_sqegère ça tout seul ou faut-il rajouter dessmp_wmb()manuellement ?Regarde du côté de
bpftrace. Tu peux écrire des sondes pour traquer les entrées qui passent pario_uring_entersans polluer tout ton système.Pour le debug,
stracec'est bien, mais y a-t-il un outil plus spécifique pour inspecter ce qui se passe dans les rings en temps réel ?C'est le futur. Les devs de moteurs de stockage (comme RocksDB) migrent déjà vers
liburingpour s'affranchir des limitations du vieux Linux AIO.Est-ce que ça remplace vraiment AIO pour les bdd type PostgreSQL ou MySQL ?
Totalement.
IORING_SETUP_SQPOLLmaintient un thread actif en permanence. Si ton trafic est sporadique, tu vas juste chauffer ton CPU inutilement. Utilise le polling uniquement pour les charges prévisibles et intenses.C'est quoi le risque réel de laisser tourner
SQPOLLsur un serveur avec une charge variable ? C'est du gâchis CPU, non ?Tu te prends un
EINVALdirect dans la tête. Le noyau refuse le buffer s'il n'est pas aligné sur la taille de secteur physique du disque.Le
O_DIRECTimpose un alignement mémoire strict. Si on oublie leposix_memalign, le kernel renvoie quoi exactement comme erreur ?C'est proportionnel à la taille de tes ring buffers. Si tu alloues de grandes files, tu dois augmenter la limite en conséquence dans
/etc/security/limits.conf. Fais un calcul simple : (taille SQ + taille CQ) * nombre de threads.Concernant le
RLIMIT_MEMLOCK, comment on calcule la valeur idéale pour éviter que le processus crashe au démarrage ?Oui, évite les vieux noyaux. Le support a énormément maturé depuis la 5.10. Les versions antérieures manquent de fonctionnalités critiques pour la gestion des erreurs de SQE.
J'ai testé en prod sur un noyau 5.4, c'était instable. Vous confirmez qu'il faut vraiment viser du 5.10+ pour être serein ?
Pour des petits paquets, le gain est surtout visible sur la réduction drastique des context switches. Avec
epoll, tu es limité par la transition user/kernel à chaque syscall. Ici, tu restes en mode polling viaIORING_SETUP_SQPOLL.