Traquer et éradiquer les fuites de mémoire sous Kubernetes

Votre téléphone vibre en pleine nuit : une alerte de production signale qu'un microservice critique vient de s'effondrer. En ouvrant vos tableaux de bord, vous constatez que le conteneur a été tué brutalement, laissant pour seule trace un statut laconique. Ce phénomène d'extinction soudaine, redouté par tous les administrateurs système, est la signature classique d'une saturation de mémoire physique gérée par la plateforme d'orchestration.
Comprendre et résoudre ces pannes nécessite de plonger sous le capot de la gestion des ressources de l'orchestrateur. Ce tutoriel vous guidera pas à pas pour identifier les fuites de mémoire, configurer des limites adaptées à la charge réelle et mettre en place des outils d'investigation directement exploitables sur vos clusters de production.
Pourquoi vos conteneurs meurent en silence
Pour comprendre le cycle de vie de la mémoire, imaginez que votre conteneur est un locataire dans un immeuble de bureaux. L'orchestrateur Kubernetes agit comme le gérant de l'immeuble. Lorsque vous définissez des limites de ressources, vous passez un contrat d'occupation.
Si votre application consomme plus de mémoire que la limite autorisée, le système d'exploitation de la machine hôte intervient pour protéger la stabilité globale. Le mécanisme OOMKilled (pour Out of Memory Killed) est le dispositif de sécurité ultime du noyau Linux qui élimine instantanément le processus le plus gourmand pour éviter un crash complet de la machine physique. Contrairement à une exception logicielle classique, ce signal ne laisse pas le temps à l'application de fermer proprement ses connexions actives.
Préparation de notre boîte à outils de diagnostic
Avant de pouvoir soigner un système malade, nous devons installer les instruments de mesure appropriés. Nous allons utiliser l'outil de ligne de commande standard et nous assurer que le serveur de métriques du cluster est opérationnel.
Vérifiez d'abord la présence du service d'agrégation des métriques en interrogeant l'API du cluster. Cette commande permet de valider que vos nœuds transmettent correctement les données d'utilisation en temps réel.
kubectl get apiservices v1beta1.metrics.k8s.ioSi le service est actif, le terminal doit renvoyer une confirmation de disponibilité. Dans le cas contraire, vous devrez déployer le serveur de métriques officiel dans votre cluster à l'aide de la commande suivante :
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yamlCette installation fournit l'infrastructure minimale pour que la commande de surveillance rapide de l'état des ressources puisse interroger l'état de consommation de vos namespaces.
Identifier le coupable : de la détection à l'analyse initiale

Une fois les outils installés, l'étape suivante consiste à intercepter les signaux faibles d'une dégradation de mémoire. Une application saine présente une courbe de consommation en dents de scie : la mémoire monte lors des traitements, puis redescend après le passage du ramasse-miettes. Une fuite de mémoire se caractérise par une croissance constante et rectiligne, insensible aux phases d'inactivité.
Analyser les événements système et les codes d'erreur
Le premier réflexe face à un conteneur défaillant est d'inspecter l'historique de son cycle de vie. L'orchestrateur garde en mémoire les raisons de la mort du précédent processus sous forme de métadonnées standardisées.
Lancez l'inspection du pod suspect en ciblant précisément les statuts de terminaison des conteneurs via la commande de description détaillée :
kubectl describe pod -n production payment-service-7f89b4b5c-2x9v4Résultat:
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Mon, 25 May 2026 14:32:01 +0200
Finished: Mon, 25 May 2026 18:14:22 +0200L'élément clé ici est le Exit Code: 137. En informatique, un code de sortie supérieur à 128 indique que le processus s'est arrêté suite à la réception d'un signal système d'arrêt d'urgence. Le code 137 correspond précisément au signal de fin de tâche immédiate (Signal 9, ou SIGKILL) envoyé par le gestionnaire de mémoire du système d'exploitation.
Une configuration de test pour provoquer le crash
Pour apprendre à manipuler et observer ce comportement sans impacter vos utilisateurs, nous allons déployer un conteneur volontairement instable. Ce fichier de configuration décrit un pod utilisant une image de test configurée pour allouer de la mémoire de façon continue jusqu'à saturer sa limite matérielle.
Créez un fichier nommé memory-leak-demo.yaml contenant les spécifications de ressources restrictives suivantes :
apiVersion: v1
kind: Pod
metadata:
name: memory-leak-demo
namespace: default
spec:
containers:
- name: leak-detector
image: polylux/stress-ng
args: ["--vm", "1", "--vm-bytes", "150M", "--timeout", "60s"]
resources:
requests:
memory: "50Mi"
cpu: "100m"
limits:
memory: "100Mi"
cpu: "200m"Dans cette configuration, l'application demande une réservation garantie de 50 Mégasegundes de mémoire physique via le paramètre requests.memory. Cependant, le paramètre limits.memory fixe un plafond infranchissable de 100 Mégasegundes. Le programme de test stress-ng tente de consommer immédiatement 150 Mégasegundes, ce qui dépasse largement le cadre autorisé.
Appliquez cette configuration sur votre cluster pour observer la réaction immédiate de l'ordonnanceur de tâches :
kubectl apply -f memory-leak-demo.yamlSurveillez en continu le statut du pod en observant l'évolution de son état grâce à l'option de suivi en direct :
kubectl get pods --watchRésultat:
NAME READY STATUS RESTARTS AGE
memory-leak-demo 1/1 Running 0 5s
memory-leak-demo 0/1 OOMKilled 1 12sLe système a détecté le dépassement en moins de dix secondes. Le conteneur a été éliminé sur-le-champ, puis l'orchestrateur a incrémenté le compteur de redémarrages pour tenter de rétablir le service.
Configurer des garde-fous robustes et collecter des dumps en production
Pour éviter que ces interruptions brutales ne nuisent à la disponibilité de vos applications en production, vous devez mettre en place une stratégie de défense en profondeur. Cela implique un dimensionnement intelligent et la capture automatique de l'état interne de la mémoire logicielle juste avant le crash.
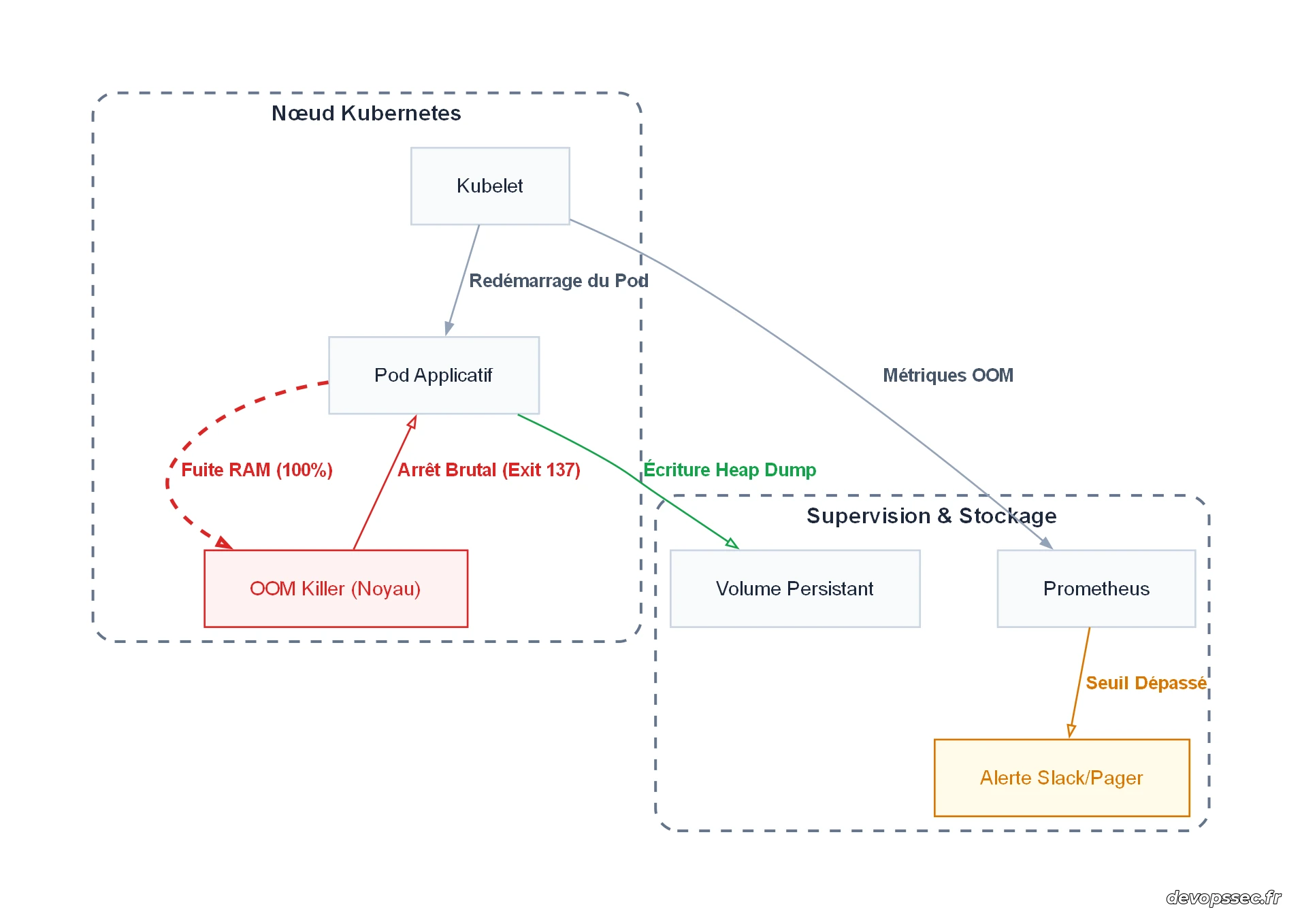
Le schéma ci-dessus illustre la chaîne de réactions lors d'une saturation de mémoire. Lorsque le conteneur atteint le plafond physique autorisé, le mécanisme d'éviction du noyau Linux intervient immédiatement. Pour résoudre efficacement le problème, notre architecture de production doit d'une part écrire un cliché de diagnostic (Heap Dump) sur un espace de stockage persistant, et d'autre part notifier l'équipe d'exploitation via la chaîne d'alerte branchée sur l'agent de supervision.
L'art du dimensionnement des ressources mémoire
L'un des pièges les plus courants consiste à copier-coller les configurations de ressources d'un service à un autre sans analyser le comportement réel de l'environnement d'exécution de votre langage de programmation (machine virtuelle Java, moteur d'exécution Node.js ou binaire compilé en Go).
| Paramètre Kubernetes | Rôle opérationnel | Comportement en cas de saturation du nœud | Comportement en cas de dépassement individuel |
|---|---|---|---|
| Requests (Demandes) | Garantit la réservation minimale d'espace physique sur le nœud lors de l'ordonnancement. | Le pod est protégé tant que sa consommation globale reste sous cette valeur de réservation. | Aucune sanction immédiate si l'hôte possède encore de la mémoire disponible. |
| Limits (Limites) | Fixe le plafond absolu d'allocation de mémoire virtuelle pour le conteneur. | Le pod est prioritaire pour l'expulsion si le nœud physique s'approche de la saturation. | Le processus principal est immédiatement tué par le noyau (OOMKilled - Code 137). |
La règle d'or pour la mémoire physique est d'éviter le sur-engagement massif. Contrairement au processeur (CPU) qui peut être ralenti ou partagé dans le temps, la mémoire physique ne peut pas être compressée. Si deux conteneurs réclament en même temps de la mémoire physique indisponible, l'un d'eux doit mourir.
Le danger du Swap sous Kubernetes
Par défaut, la mémoire d'échange (Swap) sur le disque est désactivée sur la majorité des nœuds Kubernetes pour des raisons de performances prévisibles. Tout dépassement de la limite physique déclarée se traduira donc inévitablement par un arrêt immédiat de votre processus, sans avertissement préalable.
Automatiser la capture de Heap Dumps en cas de détresse
Pour corriger une fuite de mémoire applicative, les journaux d'erreurs textuels classiques sont souvent insuffisants. Vous devez analyser l'état interne de la mémoire, appelé Heap Dump. Cette section présente une configuration de production pour une application Java Spring Boot, configurée pour sauvegarder son état sur un espace de stockage persistant avant d'être arrêtée.
Créez la configuration de production suivante sous le nom production-app-recovery.yaml :
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: diagnostics-storage-pvc
namespace: production
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: secured-payment-gateway
namespace: production
spec:
replicas: 2
selector:
matchLabels:
app: payment-gateway
template:
metadata:
labels:
app: payment-gateway
spec:
volumes:
- name: heap-dumps-volume
persistentVolumeClaim:
claimName: diagnostics-storage-pvc
containers:
- name: java-application
image: eclipse-temurin:17-jdk
env:
- name: JAVA_TOOL_OPTIONS
value: "-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/diagnostics/dumps/pay-err.hprof -XX:InitialRAMPercentage=40.0 -XX:MaxRAMPercentage=75.0"
resources:
requests:
memory: "1Gi"
cpu: "500m"
limits:
memory: "2Gi"
cpu: "1000m"
volumeMounts:
- name: heap-dumps-volume
mountPath: /diagnostics/dumpsAnalysons en détail les choix d'ingénierie appliqués dans ce déploiement de production :
- JAVA_TOOL_OPTIONS : Nous transmettons des options système directement à la machine virtuelle. L'option -XX:+HeapDumpOnOutOfMemoryError demande l'écriture automatique du fichier d'analyse dès que la mémoire de l'application sature.
- -XX:HeapDumpPath : Oriente le fichier généré vers le point de montage de notre volume persistant pour garantir que les données survivront à la destruction et au redémarrage du conteneur.
- -XX:MaxRAMPercentage=75.0 : C'est une mesure de sécurité cruciale. Nous limitons l'usage de la mémoire dynamique de l'application à 75 % de l'espace total du conteneur (2Gi). Les 25 % restants sont laissés au système d'exploitation interne, aux agents de supervision et aux outils de diagnostic pour éviter que le conteneur ne soit tué par l'orchestrateur avant d'avoir fini d'écrire son rapport d'erreur.
- diagnostics-storage-pvc : Un volume de stockage durable qui permet aux développeurs de venir récupérer le fichier d'analyse après l'incident pour l'ouvrir dans un outil d'analyse comme Eclipse Memory Analyzer.
Pour vérifier que vos fichiers d'analyse sont bien sauvegardés après un incident de production, vous pouvez lister le contenu du volume partagé à l'aide de la commande d'exécution à distance :
kubectl exec -it -n production deployment/secured-payment-gateway -- ls -lh /diagnostics/dumpsRésultat:
total 1.2G
-rw-r--r-- 1 root root 1.2G May 26 15:44 pay-err.hprofVous disposez maintenant d'un fichier de diagnostic complet et inestimable pour isoler la structure de données ou la boucle infinie responsable de la fuite de mémoire de votre application.
Dompter la mémoire pour stabiliser votre plateforme
La gestion de la mémoire au sein d'un cluster d'orchestration ne s'improvise pas. En appliquant une stratégie stricte de définition de vos besoins matériels, couplée à des mécanismes d'écriture automatique d'états d'erreur sur des volumes de stockage persistants, vous transformez des pannes système imprévisibles en sessions de correction de bugs structurées.
En tant qu'ingénieur de production, votre rôle est d'établir ce cadre de confiance pour vos équipes de développement. Configurez vos sondes, ajustez vos marges de sécurité applicative, et offrez à vos services la robustesse nécessaire pour absorber les variations de charge en toute sérénité.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
29 commentaires
Question bête : pourquoi limiter à 75% avec
-XX:MaxRAMPercentage=75.0? On perd pas de la RAM pour rien là ?J'ai testé le
memory-leak-demo.yaml, ça a bien kill le pod. Attention à ne jamais tester ça en prod, ça va spammer tes logs de redémarrage.Content que ça aide. Pour vérifier ton serveur de métriques, balance simplement un
kubectl get apiservices v1beta1.metrics.k8s.io.Si c'est vide ou en erreur, déploie le composant via le manifest officiel comme indiqué dans le tuto.
Super article, ça tombe bien j'ai mes pods qui crash en boucle avec un
OOMKilled. J'ai bien vu le code 137.Par contre, c'est quoi la commande pour voir si le
metrics-serverest bien là ?