Introduction au scale-to-zero avec KEDA

Payer pour des serveurs d'intégration ou des environnements de staging qui tournent à vide durant la nuit et les week-ends est une aberration financière que trop d'entreprises acceptent par simple résignation technique. Le concept de scale-to-zero permet de réduire instantanément la consommation de ressources de vos applications à néant lorsqu'elles ne sont pas sollicitées, divisant ainsi drastiquement vos coûts d'infrastructure cloud.
Pour imager ce mécanisme, pensez à un escalator mécanique moderne dans un centre commercial peu fréquenté. Plutôt que de fonctionner en continu à pleine vitesse et de consommer de l'électricité pour rien, l'appareil s'arrête complètement lorsqu'aucun client ne se présente, puis redémarre instantanément dès qu'un capteur détecte un pas sur la première marche.
Pourquoi KEDA pour le scale-to-zero ?
Le composant natif de Kubernetes, le Horizontal Pod Autoscaler (HPA), souffre d'une limitation historique majeure : il est incapable de réduire le nombre de réplicas d'un déploiement à zéro. La raison est logique, car le HPA s'appuie sur des métriques internes d'utilisation des ressources comme le CPU ou la mémoire vive. Si un conteneur est arrêté, il ne consomme plus aucune ressource, empêchant ainsi le HPA de générer la moindre métrique pour déclencher un redémarrage.
C'est ici qu'intervient Kubernetes Event-driven Autoscaling (KEDA). KEDA agit comme un contrôleur intelligent qui surveille des sources d'événements externes au cluster, telles que des files d'attente de messages, des bases de données ou des passerelles HTTP. Dès qu'un événement survit, KEDA réveille l'application en faisant passer le nombre de réplicas de zéro à un, puis délègue la suite de la montée en charge au HPA natif.
Installation et préparation de l'environnement
Pour déployer KEDA de manière pérenne et conforme aux standards de production, nous allons utiliser le gestionnaire de paquets Helm. Assurez-vous de disposer d'un accès administratif à votre cluster Kubernetes avant de lancer les commandes ci-dessous dans votre terminal.
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda --namespace keda --create-namespaceLa commande helm repo add enregistre le dépôt officiel de KEDA pour garantir l'accès aux versions stables les plus récentes. L'installation via helm install crée un espace de noms dédié nommé keda et y déploie l'opérateur, le serveur de métriques ainsi que les ressources personnalisées indispensables au bon fonctionnement du système.
Déploiement de notre premier scaler à zéro

Pour valider notre architecture de manière simple et robuste, nous allons mettre en place un scénario basé sur le temps. Nous allons configurer une application de traitement de données qui doit s'éteindre complètement en dehors des heures de bureau et redémarrer automatiquement le matin pour accueillir les utilisateurs.
Le déploiement de l'application cible
Nous commençons par déclarer un déploiement standard nommé worker-deployment.yaml contenant notre application fictive. Ce fichier décrit l'état de notre conteneur ainsi que ses limites de ressources initiales.
apiVersion: apps/v1
kind: Deployment
metadata:
name: worker-app
namespace: default
spec:
replicas: 0
selector:
matchLabels:
app: worker
template:
metadata:
labels:
app: worker
spec:
containers:
- name: processor
image: nginx:alpine
resources:
limits:
cpu: "200m"
memory: "256Mi"
requests:
cpu: "100m"
memory: "128Mi"Remarquez la valeur du paramètre replicas: 0 au sein de la spécification. Nous forçons délibérément l'application à démarrer dans un état totalement éteint, confirmant ainsi que KEDA prendra le contrôle exclusif du cycle de vie des pods en fonction des événements extérieurs définis.
Configuration du ScaledObject Cron
Nous allons maintenant lier notre application à un objet personnalisé de KEDA appelé ScaledObject. Ce composant contient la logique d'activation et définit le déclencheur temporel pour notre démonstration.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: worker-app
minReplicaCount: 0
maxReplicaCount: 5
cooldownPeriod: 60
triggers:
- type: cron
metadata:
timezone: Europe/Paris
start: 0 8 * * 1-5
end: 0 18 * * 1-5
desiredReplicas: "2"L'attribut scaleTargetRef pointe directement vers notre déploiement cible. Le paramètre minReplicaCount défini à 0 active explicitement le comportement de mise hors tension totale. Le bloc triggers utilise le type cron pour forcer le maintien de 2 réplicas actifs uniquement du lundi au vendredi, entre 08h00 et 18h00.
Une fois ces ressources appliquées à l'aide de la commande kubectl apply, nous pouvons valider l'état d'enregistrement de notre scaler pour vérifier sa prise en compte par le contrôleur de KEDA.
kubectl get scaledobject cron-scaledobject -n defaultRésultat:
NAME ACTIVE MINREPLICAS MAXREPLICAS AGE
cron-scaledobject True 0 5 45sComprendre la période de refroidissement
La valeur cooldownPeriod définie à 60 secondes indique à KEDA le temps d'attente nécessaire après la fin d'un événement avant de couper définitivement les conteneurs. Cela évite des arrêts et redémarrages trop fréquents si des requêtes sporadiques surviennent.
Sécurisation et optimisation pour la production
Pour un usage industriel en production, baser son dimensionnement uniquement sur le temps ne suffit pas. Nous devons concevoir une architecture capable de réagir à la charge réelle, par exemple en analysant le trafic HTTP ou le nombre de requêtes stockées dans un outil de supervision comme Prometheus, tout en protégeant les identifiants d'accès à nos métriques.
Sécurisation des accès avec TriggerAuthentication
Il est hors de question d'inscrire des jetons d'authentification ou des mots de passe en texte brut dans vos fichiers de configuration d'autoscaling. Pour résoudre cette problématique de sécurité, nous utilisons la ressource TriggerAuthentication, qui sert de passerelle sécurisée entre KEDA et nos secrets Kubernetes cryptés.
apiVersion: keda.sh/v1alpha1
kind: TriggerAuthentication
metadata:
name: keda-prometheus-auth
namespace: default
spec:
secretTargetRef:
- parameter: bearerToken
name: prometheus-credentials
key: access-tokenCet objet fait correspondre une clé de configuration attendue par le déclencheur (ici bearerToken) avec une valeur stockée de manière sécurisée dans un secret Kubernetes classique nommé prometheus-credentials. L'opérateur KEDA se charge ensuite d'injecter cette donnée de manière transparente lors de l'interrogation de l'API de supervision.
Configuration avancée du ScaledObject pour la haute disponibilité
Passons maintenant à la configuration de notre scaler de production. Ce fichier gère l'autoscaling basé sur le taux de requêtes HTTP par seconde retourné par une requête Prometheus, incluant des mécanismes de repli en cas de panne du système de métriques.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: production-http-scaler
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: worker-app
minReplicaCount: 0
maxReplicaCount: 20
cooldownPeriod: 300
idleReplicaCount: 0
fallback:
failureThreshold: 3
replicas: 3
advanced:
horizontalPodAutoscalerConfig:
behavior:
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 10
periodSeconds: 60
triggers:
- type: prometheus
metadata:
serverAddress: https://prometheus.monitoring.svc.cluster.local:9090
metricName: http_requests_per_second
query: sum(rate(http_requests_total{job="worker-app"}[2m]))
threshold: "50"
authenticationRef:
name: keda-prometheus-authAnalysons les paramètres clés de cette implémentation robuste :
- idleReplicaCount : Définit le nombre de réplicas à maintenir lorsque l'application est active mais inutilisée. Configuré à 0, il garantit le scale-to-zero complet.
- fallback : En cas de défaillance de notre serveur Prometheus (par exemple 3 échecs consécutifs), KEDA applique une politique de sécurité et force le déploiement à 3 réplicas pour éviter toute interruption de service.
- advanced.horizontalPodAutoscalerConfig : Permet de personnaliser finement la vitesse de mise à l'échelle. Nous autorisons une montée en charge instantanée (scaleUp sans stabilisation) pour absorber les pics de trafic, tout en lissant la descente (scaleDown avec une fenêtre de 5 minutes) afin d'éviter les oscillations de conteneurs.
- query : La formule PromQL calcule le nombre moyen de requêtes sur les deux dernières minutes, avec un seuil d'activation fixé à 50 requêtes par seconde et par pod.
Visualisation de l'architecture d'autoscaling
Pour mieux comprendre comment les composants s'articulent et comment les flux de données transitent au sein de votre cluster de production, voici le schéma d'intégration global de notre solution.
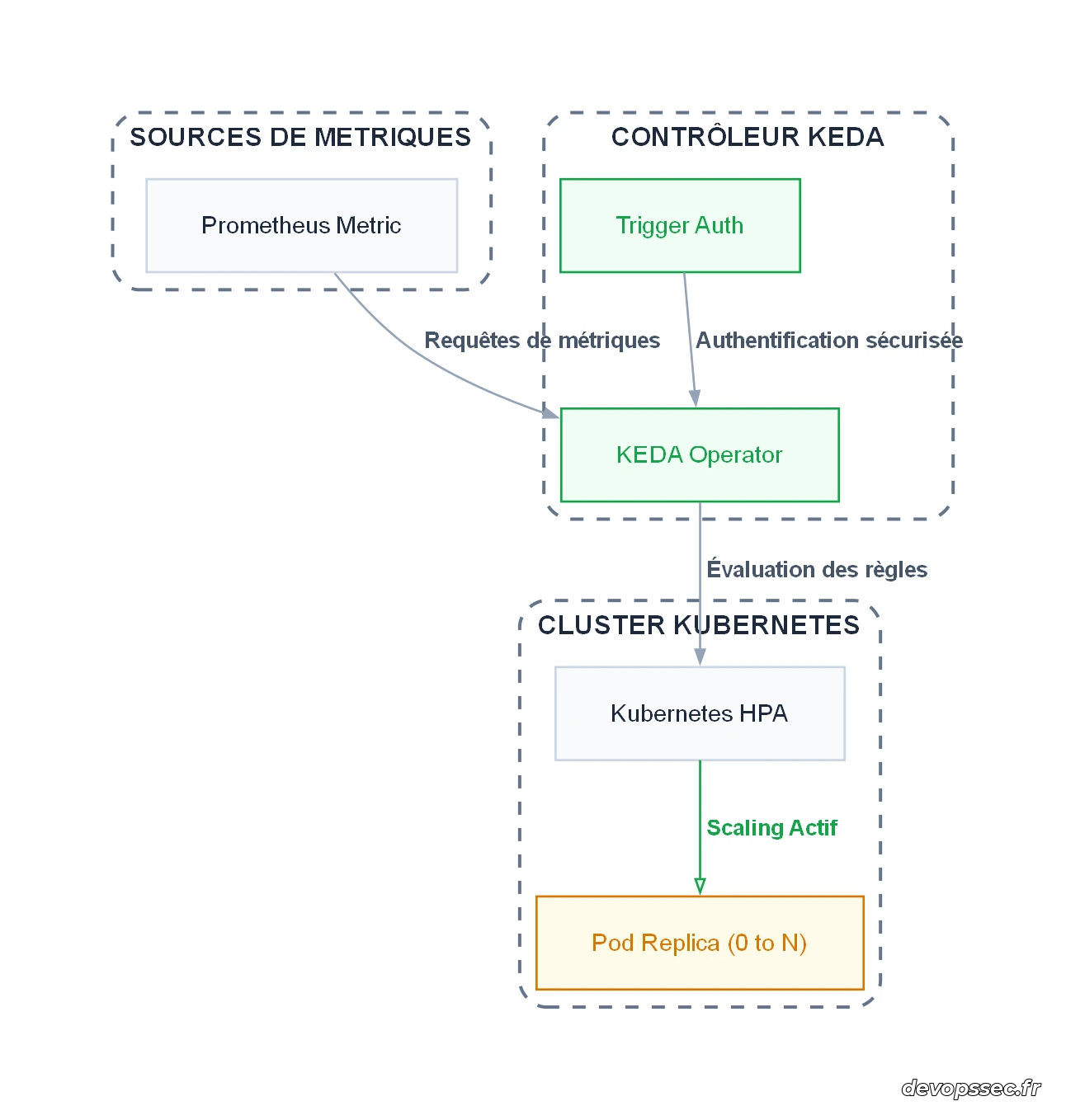
Comme l'illustre le schéma, l'opérateur KEDA interroge en continu le serveur de métriques Prometheus en utilisant les informations d'identification validées par le module de sécurité. Dès que le seuil de trafic défini est franchi, KEDA pilote dynamiquement le composant HPA natif pour ajuster le nombre de pods de l'application, passant de zéro à plusieurs instances actives en fonction de la charge détectée sur le réseau.
Attention aux démarrages à froid (Cold Starts)
Lorsque votre application passe de 0 à 1 réplica, le temps d'initialisation de votre conteneur peut créer une latence pour la première requête. Veillez à utiliser des images légères et à optimiser le temps de démarrage de vos runtimes en production pour minimiser cet impact.
Maîtrisez votre budget cloud dès aujourd'hui
L'implémentation du scale-to-zero à l'aide de KEDA représente un changement majeur dans la gestion de vos ressources Kubernetes. En combinant la puissance de l'autoscaling basé sur les événements et la sécurité renforcée des configurations de production, vous alignez précisément vos dépenses d'infrastructure sur l'activité réelle de vos services.
La prochaine étape consiste à auditer vos clusters actuels pour identifier les workloads éligibles à cette technologie, notamment dans vos environnements de développement et de recette. En appliquant ces principes de sobriété numérique, vous constaterez une réduction immédiate de votre empreinte cloud dès le prochain cycle de facturation.
Espace commentaire
Écrire un commentaire
Rejoignez la discussion
Vous devez être connecté pour poster un message.
26 commentaires
Avec plaisir. Le plus dur c'est souvent de passer le cap du premier déploiement. Reste vigilant sur les
cooldownPeriodpour éviter les oscillations.Ça marche du tonnerre. Merci pour le partage, c'est beaucoup plus clair que la doc officielle.
KEDA a besoin de droits
patchetupdatesur les déploiements. Si t'es en RBAC restreint, vérifie ça :J'ai des erreurs de permissions sur le cluster. Quel rôle je dois donner au service account de KEDA ?
Utilise
maxReplicaCountdans tonScaledObject. C'est la protection de base contre les factures imprévues.Est-ce que je peux limiter le max de pods ? J'ai peur d'un scale up massif qui me coûte une blinde.
Simple :
helm uninstall keda -n keda. N'oublie pas de supprimer aussi tes ressourcesScaledObjectavant.Une question bête : comment je désinstalle tout proprement si je veux faire marche arrière ?
Content que ça t'aide. C'est indispensable en prod pour ne pas avoir un service mort juste parce que l'outil de monitoring a une micro-coupure.
J'ai testé la config
fallback. Si Prometheus tombe, ça scale bien à 3 pods. C'est solide.Oui, tu peux en mettre plusieurs. KEDA fait un OR logique par défaut. Si l'un des triggers se déclenche, ça scale.
Peut-on mettre plusieurs triggers dans le même
ScaledObject?C'est probablement parce que KEDA et le HPA se battent. Assure-toi que tu n'as pas un autre autoscaler qui cible le même
Deployment.Ça fonctionne ! J'ai réduit ma facture de 40% sur le staging. Par contre, j'ai des logs d'erreur sur le HPA qui n'arrive pas à scaler.
Vérifie tes labels. Si
job="worker-app"ne correspond pas exactement à ce que Prometheus scrape, ça retournera rien. Fais un test direct dans l'interface Prometheus.J'ai un souci avec Prometheus. La query
sum(rate(http_requests_total{job="worker-app"}[2m]))me renvoie 0 alors que j'ai du trafic. C'est normal ?C'est le compromis. Comme précisé dans l'article, il faut des images légères. Si ton app met 30s à démarrer, ton
cooldownPerioddoit être ajusté en conséquence.Le scale-to-zero c'est bien, mais niveau latence au démarrage, c'est pas trop violent pour l'utilisateur final ?
Absolument. KEDA regarde dans le namespace où est défini le
ScaledObjectpar défaut. Si ton secret est ailleurs, tu dois le préciser dans ton YAML.J'ai une erreur sur la
TriggerAuthentication. Il ne trouve pas mon secret. Il faut le créer dans le même namespace ?Vérifie bien le fuseau horaire dans ton
ScaledObject. Si ton cluster tourne en UTC, ça peut décaler le trigger. T'as mistimezone: Europe/Paris?J'ai testé le trigger cron. Par contre, mes pods ne redémarrent pas à 8h.
kubectl get scaledobjectme ditACTIVE False.Oui, regarde du côté des
ScaledJob. C'est fait pour ça, pour éviter de laisser tourner des conteneurs après le traitement.Merci pour le tuto. Est-ce que ça marche aussi avec des jobs plutôt que des déploiements ?
Vérifie tes logs avec
kubectl logs -n keda -l app=keda-operator. T'as sûrement un problème de RBAC ou de connexion au cluster.